最近需要修正一些明星头像照片集合中的bad case,手动替换的过程中发现 http://www.manmankan.com 这个网址不错,所以打算先爬取该网站的明星头像照片对我的素材进行替换,然后再修正bad case。这样兴许可以减小工作量。
因为该网站采用了明星信息动态加载的方式,所以直接爬虫是爬不到的。解决该问题的方式有两种:
selenium+phantomjs。 Selenium是一个开源的自动化测试工具,可以用于测试web应用程序。PhantomJS是一个没有界面的浏览器。使用Python+Selenium+PhantomJS可以很方便的爬取动态加载的网页。其中PhantomJS 用来渲染解析JS,Selenium 用来驱动PhantomJS 并与 Python 的对接,Python 进行后期的数据处理。但是目前PhantomJS似乎停止维护了。python获取完整网页内容(即包括js动态加载的):selenium+phantomjs 有介绍。
分析js请求。我比较倾向于这个方式。一般动态加载的网页都是通过js向服务器端发送请求获取数据的,这样的话我们就可以截获请求,然后模拟请求进行访问了,相比之下,这种效率更高。
第二种方式如何截获请求呢?
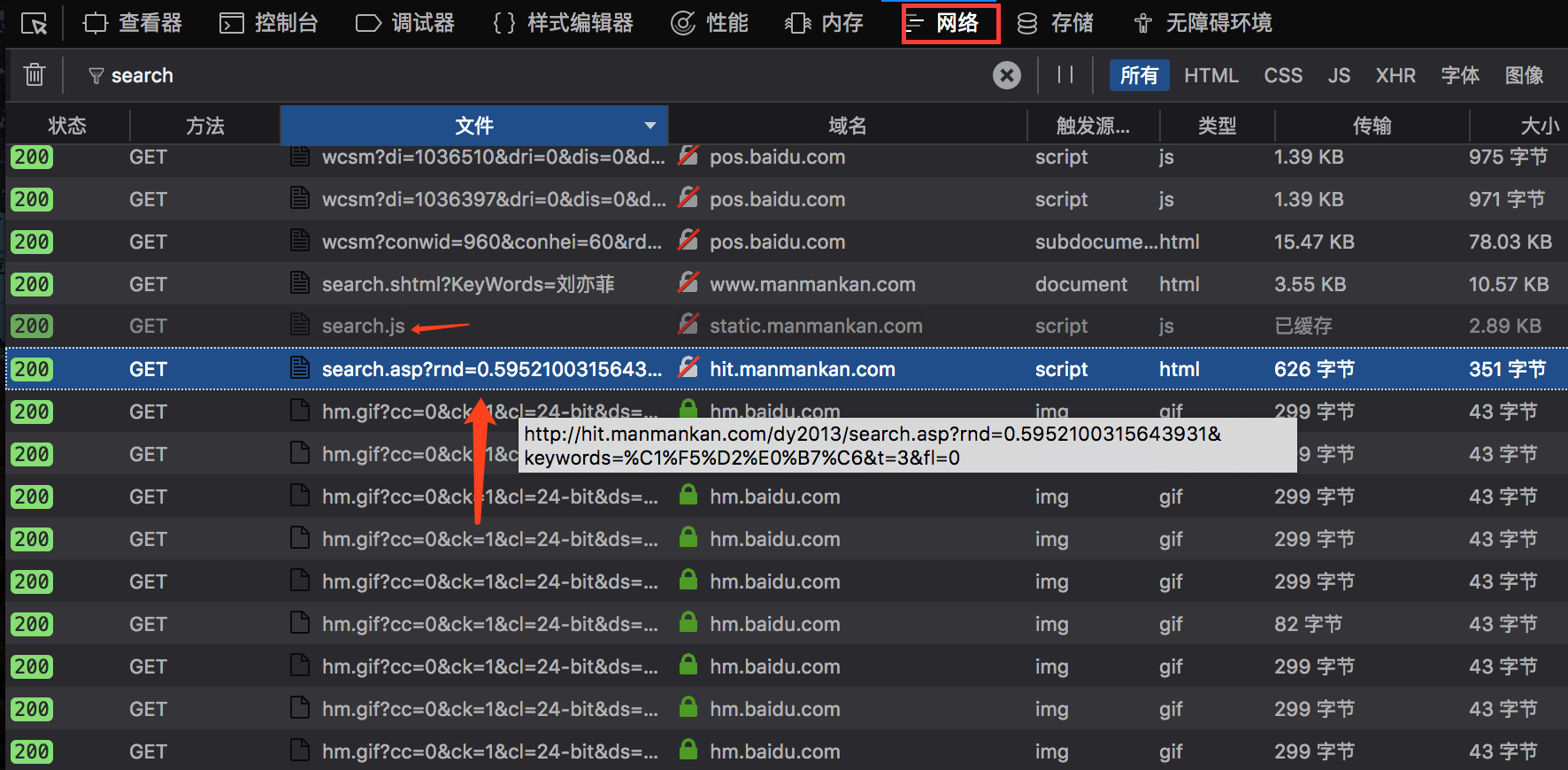
首先,使用开发版Firefox打开相关界面,使用查看器查看相关内容元素。如图所示:
在相关元素旁边有两个比较可疑的东西,loadSearch()函数和 http://hit.manmankan.com/dy2013/search.asp?rnd=0.5952100315643931&keywords=刘亦菲&t=3&fl=0 。都有search关键词,嗯,暂且记下。
然后从查看器切换到网络板块,并在网页上输入刘亦菲进行搜索,观察发生了哪些网络传输行为。这时会有好多传输信息显示,既然我们刚刚发现了search关键词,那么我们可以输入search关键词,看看剩下些什么。
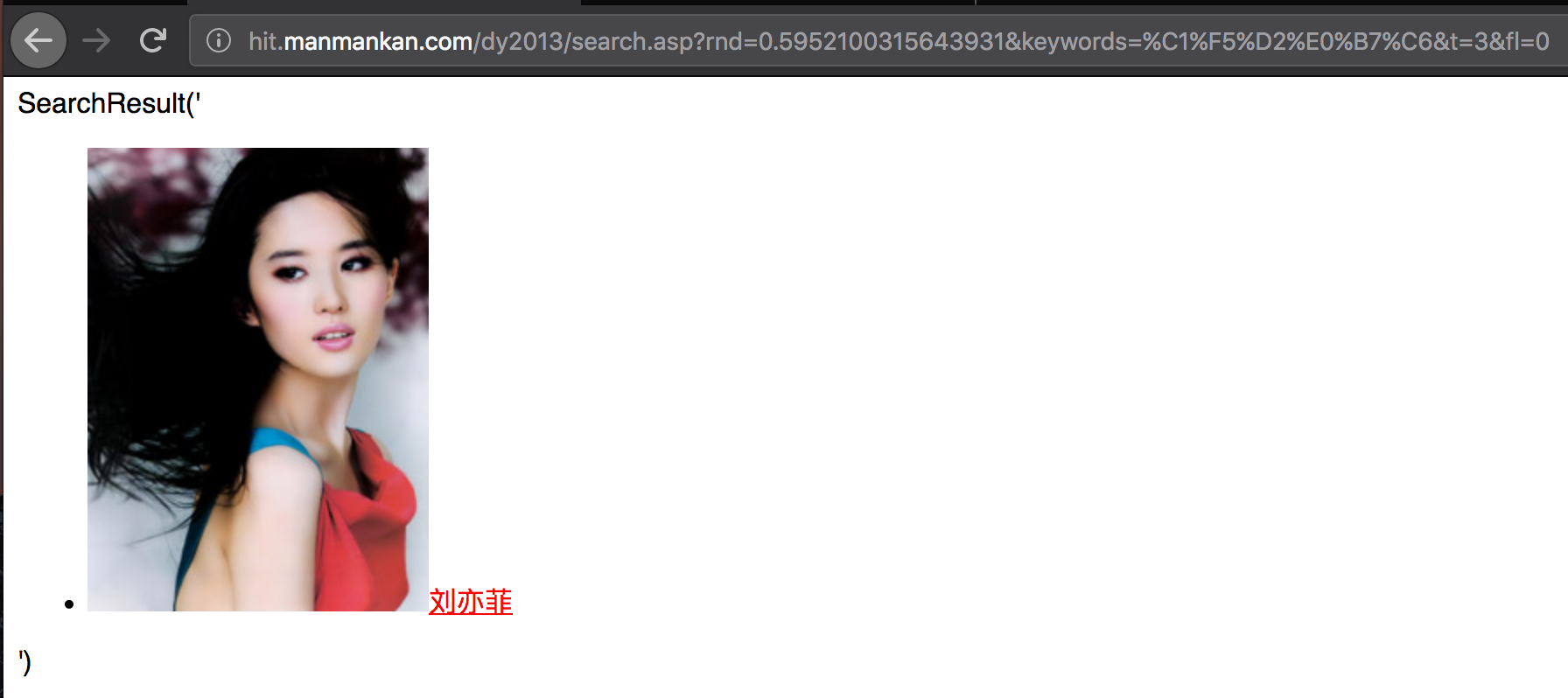
这两个东西貌似很熟悉,第二个网址和之前发现的网址很像啊,输入浏览器看看是啥。
这正是咱们需要的结果嘛。我们可以用Python访问这个网址,就会得到相关网页,然后进行正则提取就好了。
然后再看看两个网址有啥区别,貌似关键词不同,应该是中文网址进行了URL编码。那么我们只需要在Python中对中文名字进行相应编码即可。
1 2 3 http://hit.manmankan.com/dy2013/search.asp?rnd=0.5952100315643931&keywords=刘亦菲&t=3&fl=0 http://hit.manmankan.com/dy2013/search.asp?rnd=0.5952100315643931&keywords=%C1%F5%D2%E0%B7%C6&t=3&fl=0
那么我们再看看search.js文件,看看能不能找到loadSearch()函数,毕竟看名字二者存在很大关联。果不其然,发现如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 function loadSearch ( var key = QueryString("KeyWords" ); if (key == undefined || key == null || key == "" ) { $('#lilist' ).html("<span>请输入要查询的关键字</span>" ); return ; } if (key.indexOf("script" )>0 ) { return ; } key = decodeURIComponent (key); key=stripscript(key); var fid = QueryString("fl" ); if (fid == undefined || fid == null || fid == "" ) { fid=0 ; } searchlist(key,fid); } function searchlist (keywords,fid ) keywords = Trim(keywords); $('#lilist' ).html("<span>正在搜索中....</span>" ); $('#keyword' ).val(keywords); $('#kw' ).html(keywords); if (keywords == undefined || keywords == "" ) { $('#lilist' ).html("<span>请输入要查询的关键字</span>" ); return ; } var ReturnScript,ReturnValue; if (keywords != undefined && keywords != "" ) { ReturnScript=document .createElement('script' ); ReturnScript.src="http://hit.manmankan.com/dy2013/search.asp?rnd=" +Math .random()+"&keywords=" +decodeURIComponent (keywords)+"&t=3&fl=" +fid; document .body.appendChild(ReturnScript); } } function SearchResult (innerHTMLValue ) var retv=innerHTMLValue; if (retv=="" ) { $('#lilist' ).html("<span>没有找到您搜索的明星!!!</span>" ); } else { $("#lilist" ).html("" ); $("#lilist" ).html(retv); } }
来吧,我们可以编码了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 import osimport urllib2import refrom urllib import quoteimport sysreload(sys) sys.setdefaultencoding('utf8' ) def getPage (url) : header = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0" } request = urllib2.Request(url=url, headers=header) response = urllib2.urlopen(request) text = response.read() return text def getHtml (url) : page = getPage(url) html = unicode(page,'GBK' ).encode("utf8" ) return html def getImg (html, reg) : imgre = re.compile(reg) imglist = re.findall(imgre, html) return imglist def loadImg (url, path) : page = getPage(url) data = page f1 = open(path, "wb" ) f1.write(data) f1.close() def load_picname (path) : files = os.listdir(unicode(path, "utf8" )) pic_name=[] for f in files: pic_name.append(f.split("." )[0 ]) return pic_name if __name__=="__main__" : imgpath = "imgs" picname_path=r"D:\\wsp\\明星头像\\dzb" if not os.path.exists('.\\' + imgpath): os.mkdir('.\\' + imgpath) names=load_picname(picname_path) reg = r'src="([^"]*jpg)" alt="(.*?)"/>' url = "http://hit.manmankan.com/dy2013/search.asp?keywords=%s&t=3&fl=0" count=0 exist_pic_count=0 for name in names: print(count) count+=1 name=name.decode("utf8" ).encode("gbk" ) turl = (url) % name html = getHtml(turl) d = getImg(html, reg) print(html) if len(d)>0 : print("exist_pic_count: " +str(exist_pic_count)) exist_pic_count+=1 pic_name=d[0 ][1 ].strip().decode("utf8" ).encode("gbk" ) loadImg(d[0 ][0 ].strip(),(imgpath + "/%s.jpg" ) %pic_name)