论文《A Simple Convolutional Generative Network for Next Item》阅读笔记
最近,卷积神经网络(CNN)被引入到基于会话的next item推荐中。用户在会话(或序列)中交互过的item的有序集合被嵌入到二维隐矩阵中,并被视为图像,然后将卷积和池化操作应用在item embedding上。在本文中,我们首先研究了经典的基于会话的CNN推荐器,并证明在对item序列的长期依赖关系进行建模时,其生成模型和网络结构都不理想。为了解决这些问题,我们引入了一个简单但非常有效的生成模型,该模型能够从短期和长期item依赖项中学习高级表示。所提出模型的网络结构由有孔的卷积层堆叠而成,可以在不依赖于池化操作的情况下有效地增加感受野。另一个贡献是在推荐系统中有效使用残差块结构,这可以简化对更深层网络的优化。所提出的生成模型在next item推荐任务中以最短的训练时间获得了最出色的准确性。因此,它可以用作推荐基线,尤其是在用户反馈序列较长时。
1 介绍
近年来,利用用户交互的item序列(例如点击或购买)来改善现实世界的推荐系统已经变得越来越流行。当用户在会话(例如购物会话或音乐收听会话)中与在线系统互动时,会自动生成这些序列。例如,Last.fm1或Weishi2上的用户通常在一定时间段内欣赏一系列歌曲/视频,而不会受到任何干扰,即听或看。在一个会话中播放的一组音乐视频通常具有很强的相关性[6],例如,共享同一张专辑,作家或流派。因此,一个好的推荐系统应该通过利用会话中的这些序列模式来进行推荐。
经常用于这些交互序列的一类模型是递归神经网络(RNN)。 RNN通常会生成softmax输出,其中概率越大代表推荐的相关程度越高。虽然这些基于RNN的模型行之有效,如[3,15],但是其取决于整个过去的隐状态[8],不能在序列中充分利用并行计算。因此,它们的速度在训练和评估中都受到限制。
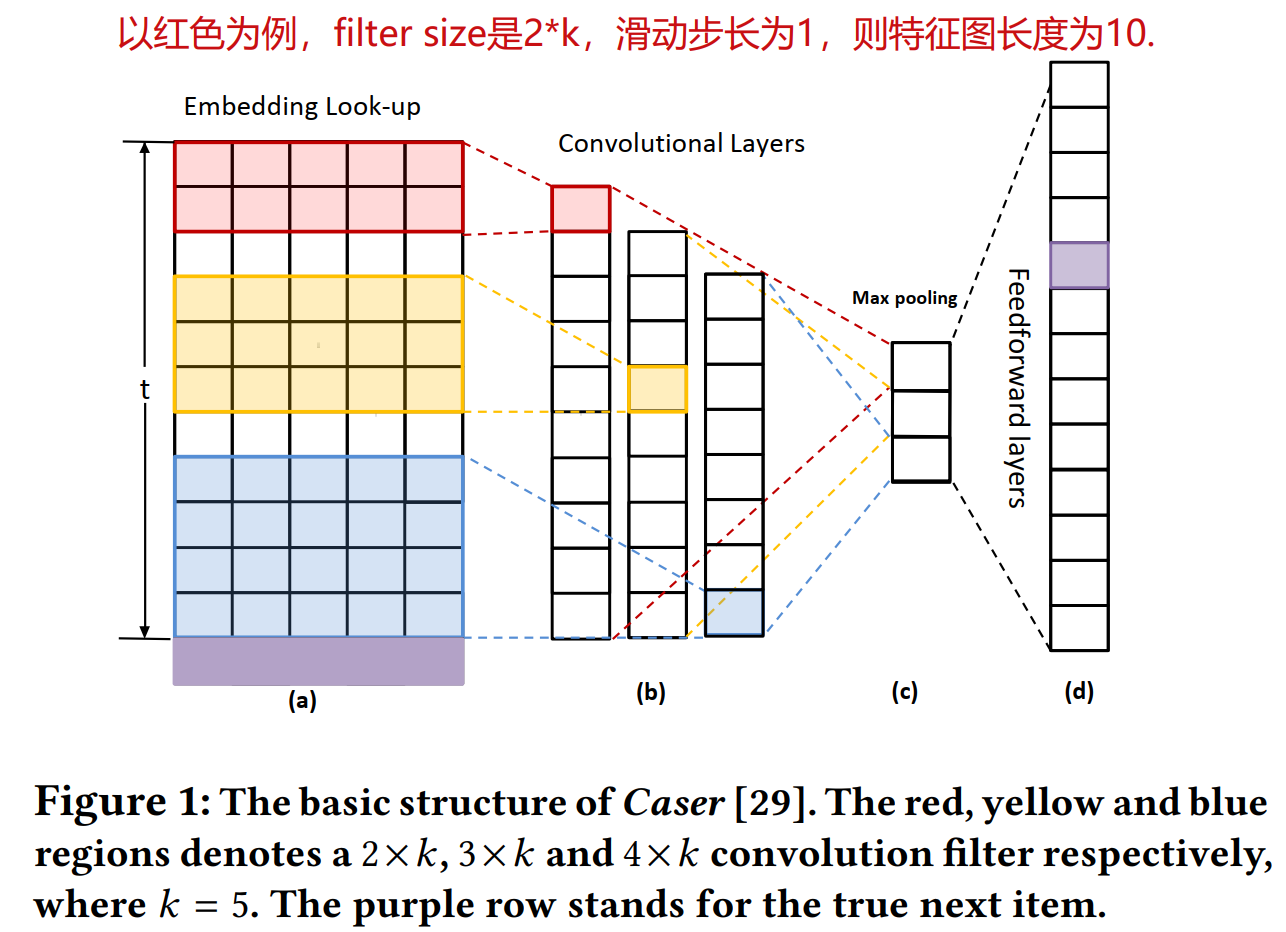
相比之下,训练CNN不依赖于先前时间步长的计算,因此可以对序列中的每个元素进行并行化。受到在图像任务中成功使用CNN的启发,一个新的序列推荐器(称为Caser [29])被提出,其放弃了RNN结构,提出了卷积序列嵌入模型,并证明了在前topN的序列推荐任务中,基于CNN的推荐器能够实现相近的或优于主流RNN模型的性能。卷积过程的基本思想是将t×k嵌入矩阵视为k维隐空间中先前t次交互的“图像”,并将序列模式视为“图像”的局部特征。执行仅保留卷积层最大值的最大池化操作以增加感受野,并处理输入序列的变化长度。图1描述了Caser的关键架构。
考虑到网络的训练速度,在本文中,我们遵循序列卷积技术的思路进行next item推荐任务。我们证明,在Caser中使用的典型网络体系结构有几个明显的缺点-例如:(1)在对长期序列数据进行建模时,用于计算机视觉的安全方案max pooling可能会丢弃重要的位置和循环信号; (最大池化有问题)(2)仅为所需item生成softmax分布无法有效使用竞争性依赖集。随着会话和序列长度的增加,这两个缺点变得更加严重。为了解决这些问题,我们引入了一个简单但完全不同的基于CNN的序列推荐模型,该模型即使在很长的item序列中也可以对复杂的条件分布进行建模。更具体地说,首先,我们的生成模型被设计为显式编码item之间的依赖关系,从而可以直接估计原始item序列上的输出序列(而不是所需item)分布。其次,代替使用低效的大型滤波器,我们将一维扩张的卷积层[31]彼此堆叠,目的是在对长期依赖进行建模时增加感受野。在上述网络结构中可以安全地移除池化层。值得注意的是,尽管发明了扩张卷积用于图像生成任务[4,26,31]中的dense prediction(稠密预测),并已应用于其他领域(例如声学[22,26]和翻译[18]任务),但是在具有大量稀疏数据的推荐系统中,尚未对此进行探索。此外,为了简化深度生成架构的优化工作,我们建议使用残差网络通过残差块包装卷积层。据我们所知,这也是采用残差学习为推荐任务建模的首次工作。这些选择的组合使我们能够解决大规模问题,并在短期和长期序列推荐数据集中获得最先进的结果。总之,我们的主要贡献包括新颖的推荐生成模型(第3.1节)和完全不同的卷积网络架构(第3.2至3.4节)
2 准备工作
本小节首先描述了序列推荐问题的定义。 然后简要概述了最近的卷积序列嵌入推荐模型(Caser)及其局限性。 最后回顾了基于序列的推荐系统的已有工作。
2.1 基于会话推荐的Top-N问题
令$x_0,x_1,..,x_{t-1},x_t$是一个用户交互的item序列,其中$x_i$是点击的item的索引。序列推荐的目标是找到一个模型,为所有的候选集生成一个排序或者类别分布$y=[y_1,y_2,…,y_n]\in R^n$,$y_i$是一个分数,也可能是待推荐的下一个item的候选集的排序。实际上,我们通常通过从y中选择n个item用于推荐任务,这就是基于会话推荐的Top-N问题。
2.2 Caser的局限
Caser的基本思想是通过嵌入查找操作(embedding look-up operation)将先前的t个item嵌入为t×k矩阵E,如图1(a)所示。矩阵的每一行向量对应一个item的隐特征。嵌入矩阵可以看作是k维隐空间中t个item的“图像”,直观地,可以将成功应用于计算机视觉中的各种CNN模型用于对item序列的“图像”进行建模。但是,有两个方面将序列建模与图像处理区分开,这使得基于CNN的模型的使用不直观。首先,在现实世界中,可变长度的item序列会产生大量不同大小的“图像”,而带有固定大小的过滤器的传统卷积结构可能会失败;其次,最有效的图像过滤器,例如3× 3和5×5不适用于序列“图像”,因为这些小的过滤器(就行方向而言)不适合捕获全宽度嵌入向量的表示。为了解决上述限制,Caser中的过滤器会通过大型过滤器在序列“图像”的所有列上滑动。也就是说,过滤器的宽度通常与输入“图像”的宽度相同,其高度由一个滑动窗口确定,滑动窗口一次滑过2-5个item(图1(a))。卷积后生成可变长度的特征图(图1(b)),为确保所有图具有相同的大小,对每个图执行max pooling,仅选择每个特征图的最大值,从而得到1×1映射(图1(c))。最后,将所有过滤器的1×1映射连接起来形成特征向量,然后是softmax层,产生下一项的概率(图1(d)))。注意,由于它不能解决下面讨论的主要问题,因此我们省略了图1中的垂直卷积。
根据以上对Caser中卷积的分析,可能会发现当前设计存在一些缺点。首先,max pooling运算符有明显的缺点,无法区分重要特征在特征图中出现的次数仅发生一次或多次,并且忽略了它发生的位置。 max pooling运算符虽然可以安全地用于图像处理时(使用小型池化过滤器,例如3×3),但是其可能对建模长期序列(使用大型过滤器,例如1×20)有害。其次,在对复杂关系或长期依赖进行建模时,Caser中仅适合一个隐层卷积层的浅层网络结构可能会失败。最后一个重要的缺点来自next item的生成过程,我们将在第3.1节中详细介绍。
2.3 相关工作
序列推荐中的早期工作主要依赖于马尔可夫链[5]和基于特征的矩阵分解[12,32–34]方法。与神经网络模型相比,基于马尔可夫链的方法无法对序列数据中的复杂关系进行建模。例如,在Caser中,作者表明马尔可夫链方法无法对联合级序列模式进行建模,并且不允许item序列中的跳跃行为。基于因子分解的方法(例如因子分解机)通过序列中item的向量和对序列建模。但是,这些方法没有考虑item的顺序,也不是专门为序列推荐而发明的。
与传统模型相比,最近的深度学习模型显示了最新的推荐准确性。此外,RNN是一类深层神经网络,几乎在序列推荐领域占据主导地位。例如,[15]提出了一种基于排序损失的门控循环单元(GRURec)体系结构,用于基于会话的推荐。在后续论文中设计了各种RNN变体,以针对不同的应用场景扩展经典的RNN变体,例如通过添加个性化[25],内容[9]和上下文特征[27],注意力机制[7、20]和不同的排序损失函数[14]。相比之下,基于卷积神经网络的序列推荐模型更具挑战性,而且探索也少得多,因为卷积不是捕获序列模式的自然方法。据我们所知,迄今为止,仅提出了两种类型的序列推荐架构:第一种是基于Caser的标准2D CNN,而第二种是设计用于建模高维特征的3D CNN [30]。与上述示例不同,我们计划使用有效的扩展卷积过滤器和残差块来研究一维CNN的效果,以构建推荐架构。
3 模型设计
3.1 一个简单的生成模型
在本节中,我们介绍一个直接作用于item交互序列的简单但非常有效的生成模型。 我们的目的是估计原始item交互序列上的分布,该分布可用于精确计算item的可能性并生成用户希望进行交互的next item。 令p(x)为item序列x={x0, …, xt}的联合分布。 为了建模p(x),我们可以通过链式规则将其分解为条件分布的乘积。
$$
p(x)=\prod_{i=1}^t{p(x_i|x_{0:i-1},\theta)p(x_0)} \tag{1}
$$
由于神经网络具有建模复杂非线性关系的能力,因此本文中我们通过堆叠一维卷积网络对user-Item交互的条件分布进行了建模。更具体地说,网络接收$x_{0:t-1}$作为输入,并输出可能的$x_{1:t}$上的分布,其中$x_t$的分布是我们的最终期望。例如,如图2所示,$x_{15}$的输出分布由$x_{0:14}$确定,而$x_{14}$由$x_{0:13}$确定。值得注意的是,在先前的序列推荐文献中,例如Caser,GRURec和[20、25、28、30],他们仅对单个条件分布 $p(x_i|x_{0:i-1},θ)$ 进行建模,而不是对所有条件概率 $\prod_{i=1}^t{p(x_i|x_{0:i-1},θ)p(x_0)}$进行建模。在上述示例的上下文中,假设给出$\lbrace x_0,…, x_{14}\rbrace$,像Caser这样的模型仅估算下一项$x_{15}$的概率分布(即softmax)(另请参见图1(d)),而我们的生成方法会估算$\lbrace x_0,…, x_{14},x_{15}\rbrace$中所有单个item的分布。生成过程的比较如下所示。
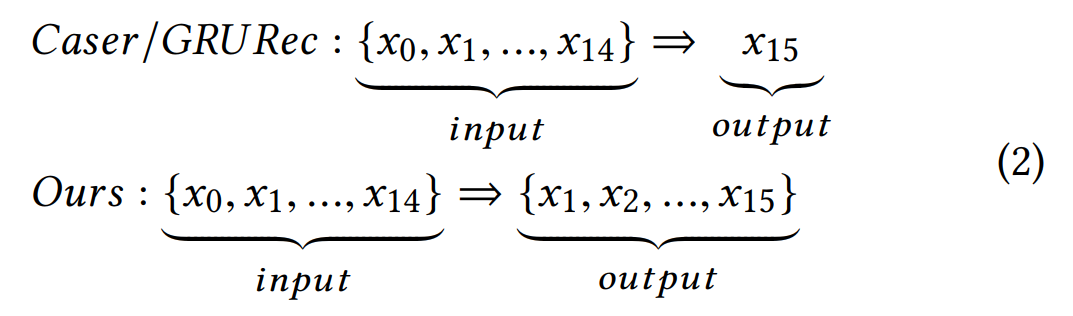
显然,我们提出的模型在捕获所有序列关系的集合方面更为有效,而Caser和GRURec未能明确建模$\lbrace x_0,…, x_{14}\rbrace$之间的内部序列特征。 在实践中,**为了解决该缺陷(这种缺陷是否对推荐效果有影响?)**,这样的模型通常通过数据增强技术[28](例如,对输入序列进行填充,拆分或移位)生成大量子序列(或子会话)以进行训练。如方程式(3)所示(请参阅[20、25、29、30])。
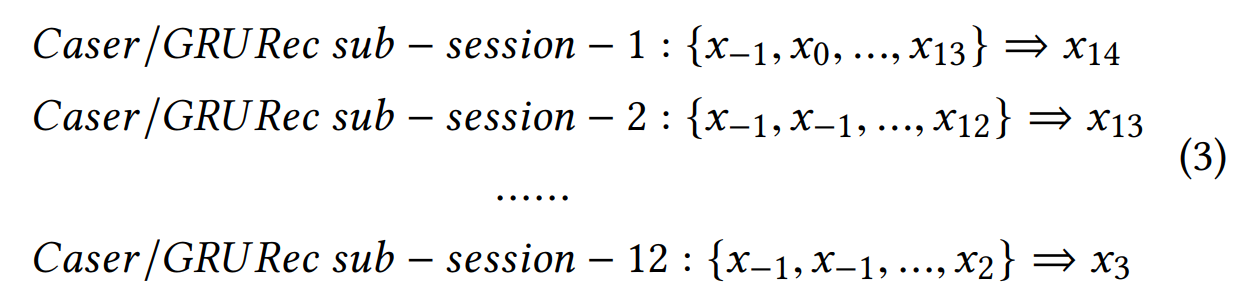
尽管有效,但是由于每个子会话的单独优化,上述生成子会话的方法不能保证最佳结果。 另外,分别优化这些子会话将导致相应的计算成本。 我们的实验部分也报告了与经验结果的详细比较。
3.2 网络结构
3.1.1 嵌入查找层:给定item序列$\lbrace x_0,…,x_{t}\rbrace$,模型通过查找表检索前t个item$\lbrace x_0,…,x_{t-1}\rbrace$中的每一个,并堆叠这些item的embedding。假设嵌入维数为2k,其中k可以设置为卷积网络中内部通道的数量。这将生成尺寸为t×2k的矩阵。请注意,与Caser在卷积期间将输入矩阵视为2D“图像”不同,我们提出的架构通过1D卷积过滤器学习嵌入层,稍后将对其进行介绍。
3.2.2 扩张层:如图2(a)所示,标准滤波器只能与感受野线性地进行卷积,其深度取决于网络的深度,这使得很难处理长期序列。类似于Wavenet [22],我们采用扩张卷积来构造提出的生成模型。扩张的基本思想是通过用零扩张将卷积滤波器应用于大于其原始长度的场。这样,由于它使用较少的参数,因此效率更高。因此,扩张过滤器也称为带孔过滤器或稀疏过滤器。另一个好处是,扩展的卷积可以保留输入的空间尺寸,这对于卷积层和残差结构都使堆叠操作更加容易。
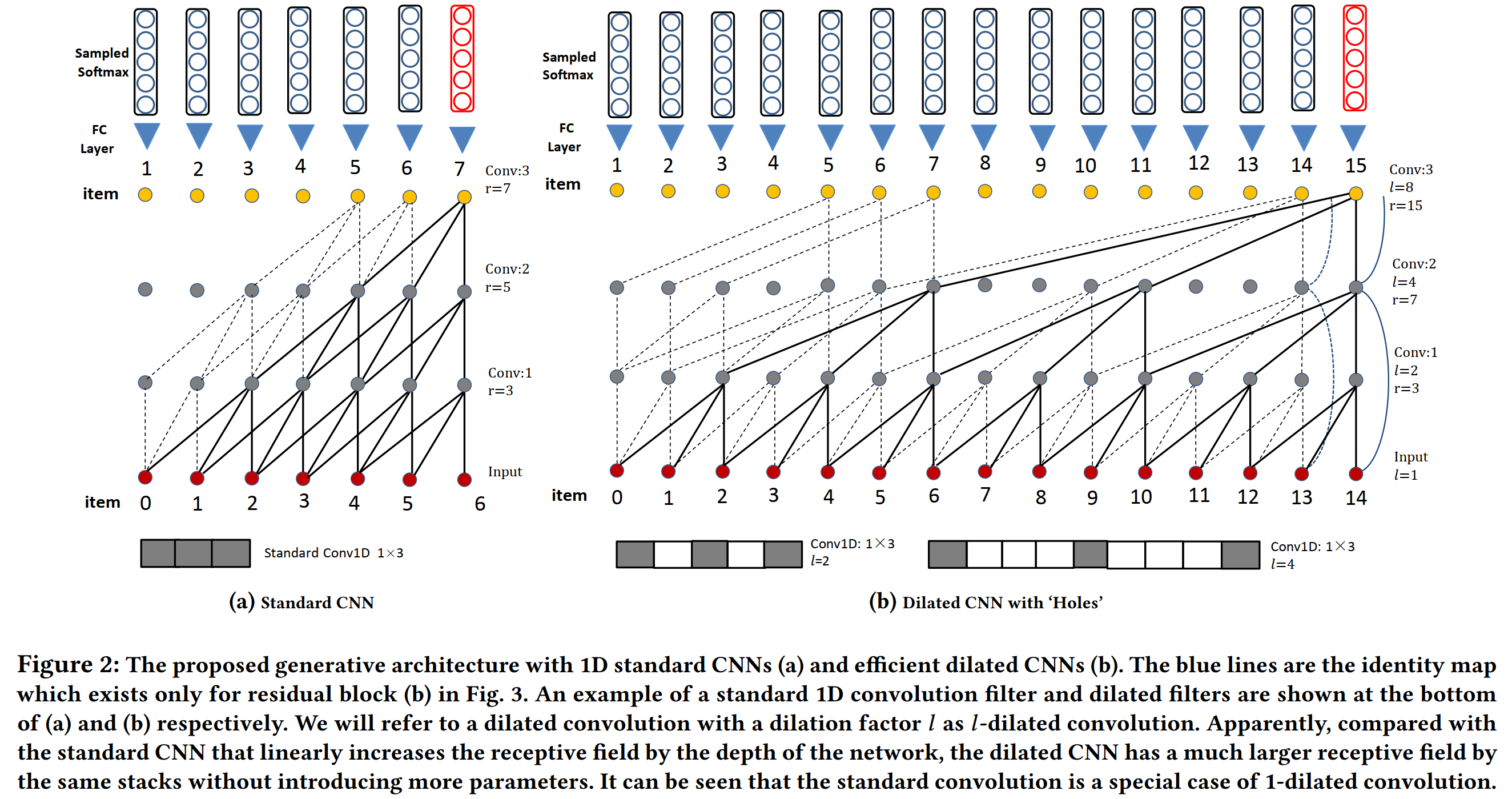
图2显示了标准卷积和扩张卷积之间的网络比较。 (b)中的扩张因子为1、2、4和8。为了描述网络架构,我们分别将感受野,第j卷积层,通道和扩张分别表示为$r, F_j, C和l$。通过将卷积滤波器$f$的宽度设置为3,我们可以看到扩张的卷积(图2(b))允许感受野的大小成指数增长$(r=2^{j+1}-1)$,而相同的堆叠标准卷积的结构(图2(a))仅具有线性感受野 $(r=2j+1)$。形式上,使用扩张$l$,从位置i开始的过滤器窗口为:
$$
[x_i\quad x_{i+l}\quad x_{i+2l}\quad …\quad x_{i+(f-l)\cdot l}]
$$
下面给出了item序列中的元素h的一维扩张卷积算子$*l$:
$$
(x \ast_{l} g)(h)=\sum_{i=0}^{f-1}{x_{h-l\cdot x}\cdot g(i)}
$$
其中g是过滤功能。 显然,扩张的卷积结构对长期item序列建模更有效,因此在不使用较大过滤器或变得更深的情况下更为有效。 实际上,为了进一步增加模型容量和接感受野,只需要通过堆叠例如1、2、4、8、1、2、4、8多次重复图2中的架构即可。
3.2.3一维变换:尽管我们的扩张卷积算子依赖于2D输入矩阵E,但所提出的网络架构实际上是由所有1D卷积层组成的。 为了对2D embedding输入建模,我们执行简单的reshape操作,这是执行1D卷积的前提。 具体而言,将2D矩阵E从t×2k整形为大小为1×t×2k的3D张量T,其中2k被视为“图像”通道,而不是Caser中标准卷积滤波器的宽度。 图3(b)说明了reshape过程:
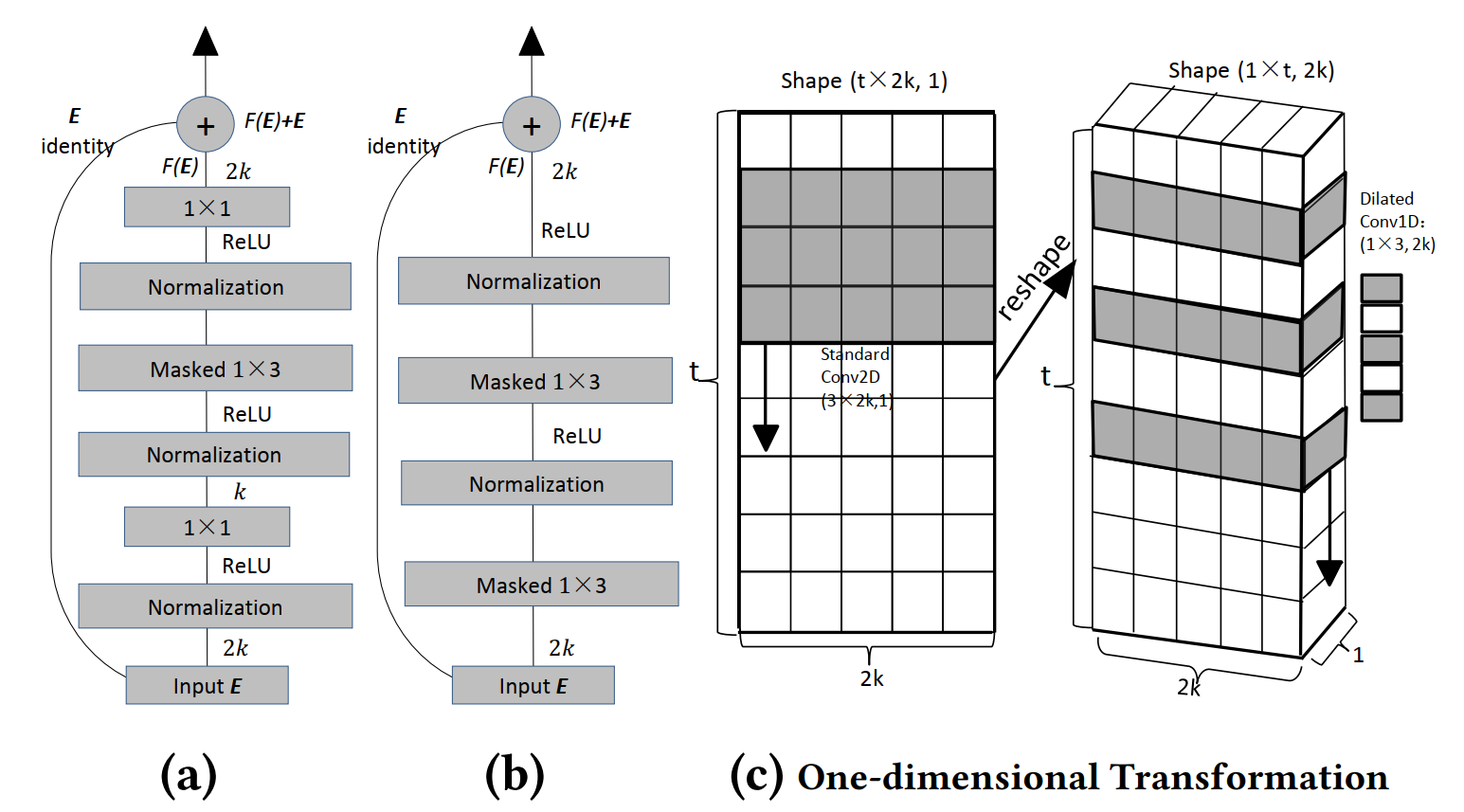
Figure 3: Dilated residual blocks (a), (b) and one-dimensional transformation (c). (c) shows the transformation from the 2D filter (C=1)(left) to the 1D 2-dilated filter (C=2k) (right); the vertical black arrows represent the direction of the sliding convolution. In this work, the default stride for the dilated convolution is 1. Note the reshape operation in (b) is performed before each convolution in (a) and (b) (i.e., 1 × 1 and masked 1 × 3), which is then followed by a reshape back step after convolution.
3.3 蒙版卷积残差网络
尽管增加网络层的深度可以帮助获得更高级别的特征表示,但它也很容易导致梯度消失问题,这使学习过程变得更加困难。为了解决退化问题,针对深度网络引入了残差学习[10]。尽管残差学习在计算机视觉领域取得了巨大的成功,但尚未出现在推荐系统的文献中。
残差学习的基本思想是将多个卷积层堆叠在一起作为一个块,然后采用跳跃连接方案,将前一层的特征信息传递到后一层。跳跃连接方案允许显式拟合残差映射而不是原始恒等映射,这可以维护输入信息并扩大传播梯度。形式上,将所需的映射表示为H(E),我们让残差块拟合F(E)= H(E)-E的另一个映射。现在,将所需的映射通过按位相加的方式转为F(E)+ E(假设F(E)和E具有相同的维数)。正如[10]中所证明的那样,优化残差映射F(E)比原始的未引用映射H(E)容易得多。受[11,18]的启发,我们在图3(a)和(b)中引入了两个残差模块。
在图3(a)中,我们用残差块包裹每个扩张卷积层,而在图3(b)中,我们用不同的残差块包裹每两个扩张层。即,在块(图3b)的设计中,输入层和第二卷积层应通过跳跃连接(即,图2中的蓝线)连接。具体地,每个块由归一化、激活、卷积层和跳跃连接以特定的顺序组合而成。在这项工作中,我们在每个激活层之前都采用了最新的层归一化方法[1],因为与批量归一化方法相比[16],它非常适合序列处理和在线学习。
关于这两个残差网络的性质,(a)中的残差块由3个卷积滤波器组成:一个大小为1×3的膨胀滤波器和两个大小为1×1的常规滤波器。引入1×1滤波器来改变C的大小,以减少1×3的核要学习的参数。第一个1×1滤波器(接近图3(a)中的输入E)将C从2k更改为k,而第二个1×1滤波器进行相反的转换,以保持下一个堆叠操作的的空间维度。为了显示(a)中1×1滤波器的有效性,我们计算了(a)和(b)中参数的数量。为简单起见,我们省略了激活层和normalization层。如我们所见,没有1×1滤波器的1×3滤波器的参数数目为$1\times 3\times 2k\times 2k=12k^2$(即(b)中)。在(a)中,要学习的参数数量为$1\times 1\times 2k\times k + 1\times 3\times k\times k + 1\times 1\times k\times 2k=7k^2$。(a)和(b)中的残差映射表示为:

其中$\sigma$和$\psi$表示ReLU和层归一化,$W_1$和$W_3$表示标准1×1卷积的卷积权重函数,$W_2, W_2^{‘}$和$W_4^{‘}$表示尺寸为1×3的l型卷积滤波器的权重函数。 注意,为了简化符号省略了偏置项。
3.3.1 Dropout-mask:为避免将来出现信息泄漏问题,我们为一维扩张卷积提出了一种基于掩码的dropout技巧,以防止网络接触到将来的item。 具体而言,当预测$p(x_i|x_{0:i-1})$时,不允许卷积滤波器使用$x_{i:t}$的信息。 图4显示了执行卷积的几种不同方式。 如图所示,可以通过填充输入序列(d)或将输出序列移位几个时间步(e)来实现我们的dropout-masking操作。(e)中的填充方法很可能导致序列中的信息损失,尤其是对于短序列。 因此,在这项工作中,我们应用了在(d)中的填充策略,其填充大小为$(f-1)*l$。

3.4 最后一层,网络训练和生成
如上所述,在卷积结构最后一层中的矩阵(见图2)由$E^o$表示,保持了输入E的相同尺寸,即$E^o\in R^{t\times 2k}$。但是,输出应为包含输出序列$x_{1:t}$中所有项的概率分布的矩阵或张量,其中$x_t$的概率分布是生成前N个预测的期望值。为此,我们可以简单地在图2中最后一个卷积层的顶部再使用一个卷积层,其过滤器的大小为$1×1×2k×n$([卷积核的高度,卷积核的宽度,图像通道数/输入 channel,卷积核个数/输出 channel]),其中n是项数。按照图3(c)中的一维变换的过程,我们获得了预期的输出矩阵$E^p \in R^{t\times n}$,其中softmax操作之后的每个行向量都表示$x_i(0<i≤t)$上的分类分布。优化的目的是使训练数据的对数似然性最大化。显然,在数学上最大化$log p(x)$等效于最小化$x_{1:t}$中每个item的二项分布交叉熵损失之和。对于具有数千万个item的真实推荐系统,可以采用负采样策略来绕过全softmax分布的生成,其中将1×1卷积层替换为权重矩阵为$E^g\in R^{2k\times n}$的全连接层(FC)。例如,我们可以应用采样的softmax [17]或基于核的采样[2]。这些负采样策略的推荐精度几乎与采样大小经过适当调整的全softmax方法相同。
为了进行比较,我们仅预测评估中的下一个item,然后停止生成过程。然而,该模型能够简单地通过将预测的一个item(或序列)输入网络以预测下一个item来生成item序列,因此在生成阶段的预测是连续的。这与大多数实际推荐方案相匹配,在观察到当前推荐方案后,将执行下一个操作。但是在训练和评估阶段,可以并行进行所有时间步的条件预测,因为输入项x的完整序列已经可用。
实验细节见下文。
参考文献
1 A Simple Convolutional Generative Network for Next Item Recommendation

