COLD Towards the Next Generation of Pre Ranking System
目前主流的以双塔结构为基础的粗排系统被定义为第三代粗排系统,其离线计算得到用户和广告的向量,同时以向量内积的方式在线计算得到用户和广告的分数进行排序过滤。该架构的优点在于性能开销小,但是也有如下缺点:
- 模型表达能力受限;
- 离线计算用户和广告向量的时间久,较难捕捉到数据分布漂移;
- 模型更新频率受限,即很难保证用户和广告的索引同时切换,而这是非常重要的,不同步会损害模型的性能。

基于以上问题,论文提出了一种新的粗排系统,在模型表达能力和算力消耗两方面进行了优化(也就是重新考虑模型设计和系统设计),使得可以上线较复杂的模型。优化点主要有3个:
- COLD模型是一个七层的全连接网络,其使用SE进行了特征选择,受益于SE,算力消耗可控。且加入了交叉特征;
- 使用了一些优化技巧降低算力消耗,包括并行计算,半精度计算进行推理加速;
- COLD模型以在线学习的方式运行,解决数据分布漂移的问题;
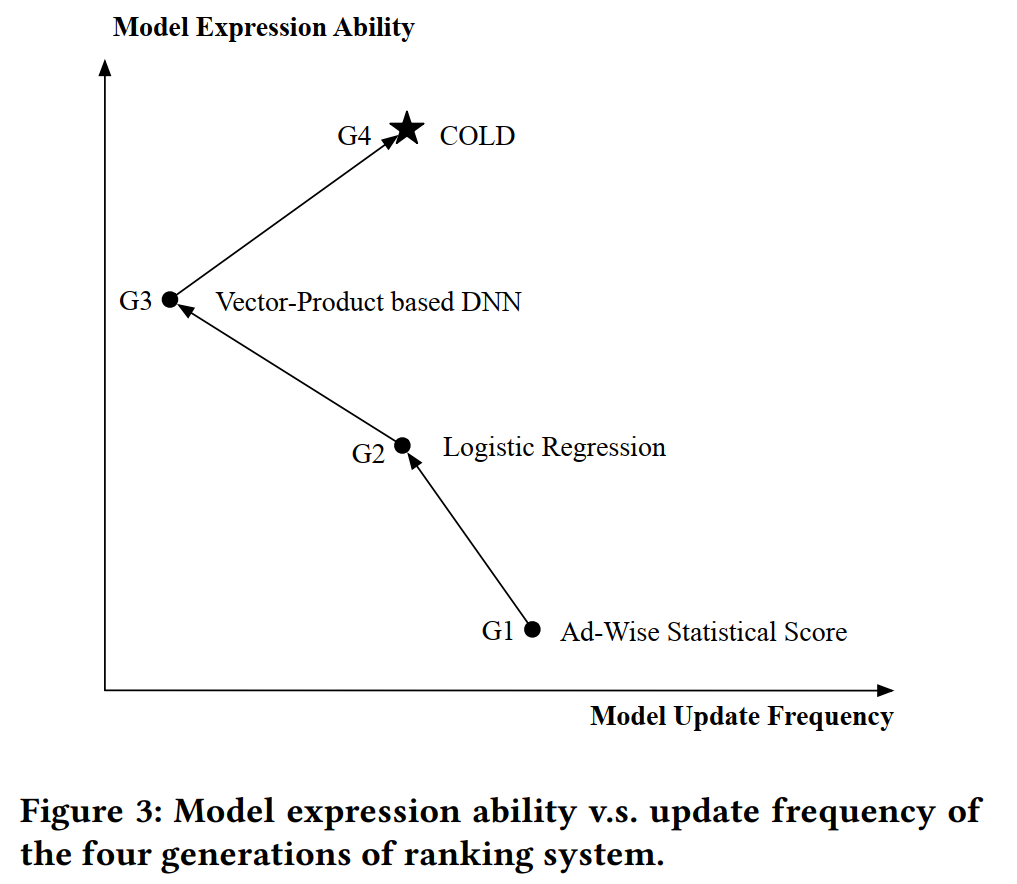
如图3所示,COLD实现了模型表达能力和更新频率之间的平衡。目前COLD被广泛应用于阿里巴巴业务线,并实现了6%的RPM提升。
下面来谈谈COLD的细节:
- 设计灵活的模型结构降低平衡模型性能和算力成本。论文使用GwEN作为base model,这是在线模型的早期版本。GwEN分组的目的是借鉴cnn局部感受野的思想,降低参数量级。此外要保证模型尽量轻,且保证模型的表达能力。使模型变轻有很多方法,例如剪枝,特征选择,NAS等,论文选择了一种叫做SE的特征选择方法。SE最开始被应用于CV。
- 工程优化tricks,推理加速。工程优化指的是在线推断环节,其分为两个部分:交叉特征计算和稠密网络计算。在阿里定向广告系统中,粗排的线上打分主要包含两部分:特征计算和网络计算。特征计算部分主要负责从索引中拉取用户和广告的特征并且进行交叉特征的相关计算。而网络计算部分,会将特征转成embedding向量,并将它们拼接进行网络计算[1]。特征计算环节加速的trick有多线程加速,列计算转换;稠密网络计算环节加速的trick有GPU加速(混合精度加速)。
- 在线服务架构方面,我个人理解没有过多的创新。如图7所示。

关于实验结果可以参考文献[1],值得注意的是论文使用了GAUC指标评测模型。
参考
[1] 阿里定向广告最新突破:面向下一代的粗排排序系统COLD
certain metrics 某些指标;
vector-product 向量内积;
Shortcomings 缺点;
suboptimal performance 欠佳;
lightweight 轻量级;

