多任务学习系列之PLE
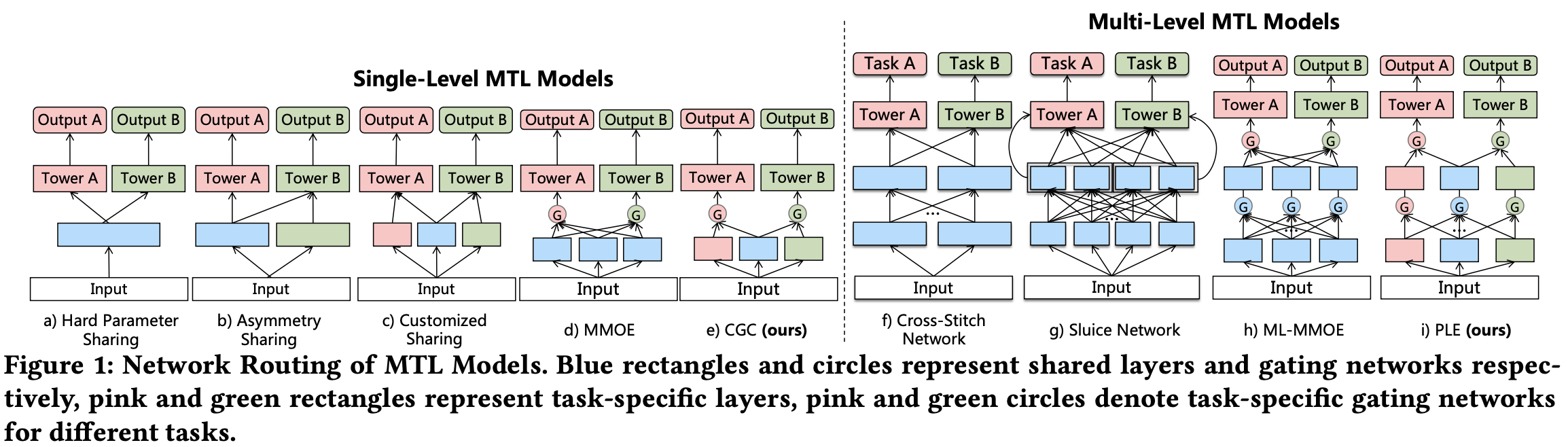
多任务学习的典型工作有多独立塔DNN,多头DNN,MOE,MMOE等工作,今天介绍的是腾讯的PLE(Progressive Layered Extraction)模型,PLE重点解决了多任务学习中存在的跷跷板现象(seesaw phenomenon)。多任务学习(MTL)并被证明可以通过任务之间的信息共享来提高学习效率。 然而,多个任务经常是松散相关甚至是相互冲突的,这可能导致性能恶化,这种情况称为负迁移 。 在论文中提到,通过在真实世界的大规模视频推荐系统和公共基准数据集上的大量实验,发现现有的 MTL 模型经常以牺牲其他任务的性能为代价来改进某些任务,当任务相关性很复杂并且有时依赖于样本时,即与相应的单任务模型相比,多个任务无法同时改进,论文中称之为跷跷板现象。
为了解决跷跷板和负迁移的现象,论文提出了一种共享结构设计的渐进式分层提取(PLE)模型。其包含两部分, 一部分是一种显式区分共享专家塔和特定任务专家塔的门控 (CGC) 模型,另一部分是由单层CGC结构扩展到多层的PLE模型。
1 Customized Gate Control (CGC) Model
为了实现和单任务相似的性能,论文显式分离了任务共享专家部分和任务独享专家部分,并提出了CGC(如下图所示)。顶部是一些和任务相关的多层塔网络,底部是一些专家模块,每个专家模块由多个专家网络组成。专家模块分为两类,一类是任务共享的专家模块,负责学习任务的共享模式,一类是任务独享的专家模块,负责学习任务的独享模式。每个塔网络从所有专家模块(共享专家模块和独享专家模块)学习知识。

在CGC中,所有专家模块的输出通过一个门控网络融合。门控网络是一个单层前馈网络,使用softmax作为激活函数。input作为选择器(selector)计算所有选择向量(the selected vectors)的加权和( input as the selector to calculate the weighted sum of the selected vectors),这句话有点绕,其实就是基于input生成选择概率,然后基于选择概率融合所有专家模块的输出,所以input被称作selector;selected vectors就是专家模块的输出,它们基于选择概率被选择了。任务k的门控网络形式化如下:

上面的公式其实很简单,$w^k(x)$就是门控网络的参数矩阵,$S^k(x)$是所有专家模块的输出,$g^k(x)$是门控网络的输出,任务k的输出就是$y^k(x)=t^k(g^k(x))$,$t^k(x)$是任务k的塔网络。
**和MMOE相比,CGC增加了任务的独享专家网络,使其更聚焦于学习任务的独享模式**。
2 Progressive Layered Extraction
PLE将单层CGC结构扩展到了多层,用于学习越来越深的语义表示。那么在多层CGC中,独享专家模块和共享专家模块怎么融合上一层网络的输出是一个需要考虑的问题。为此,论文提出了多级提取网络,其结构类似于CGC,但是定义了各个专家模块更新的逻辑。多级提取网络的结构如下图所示。
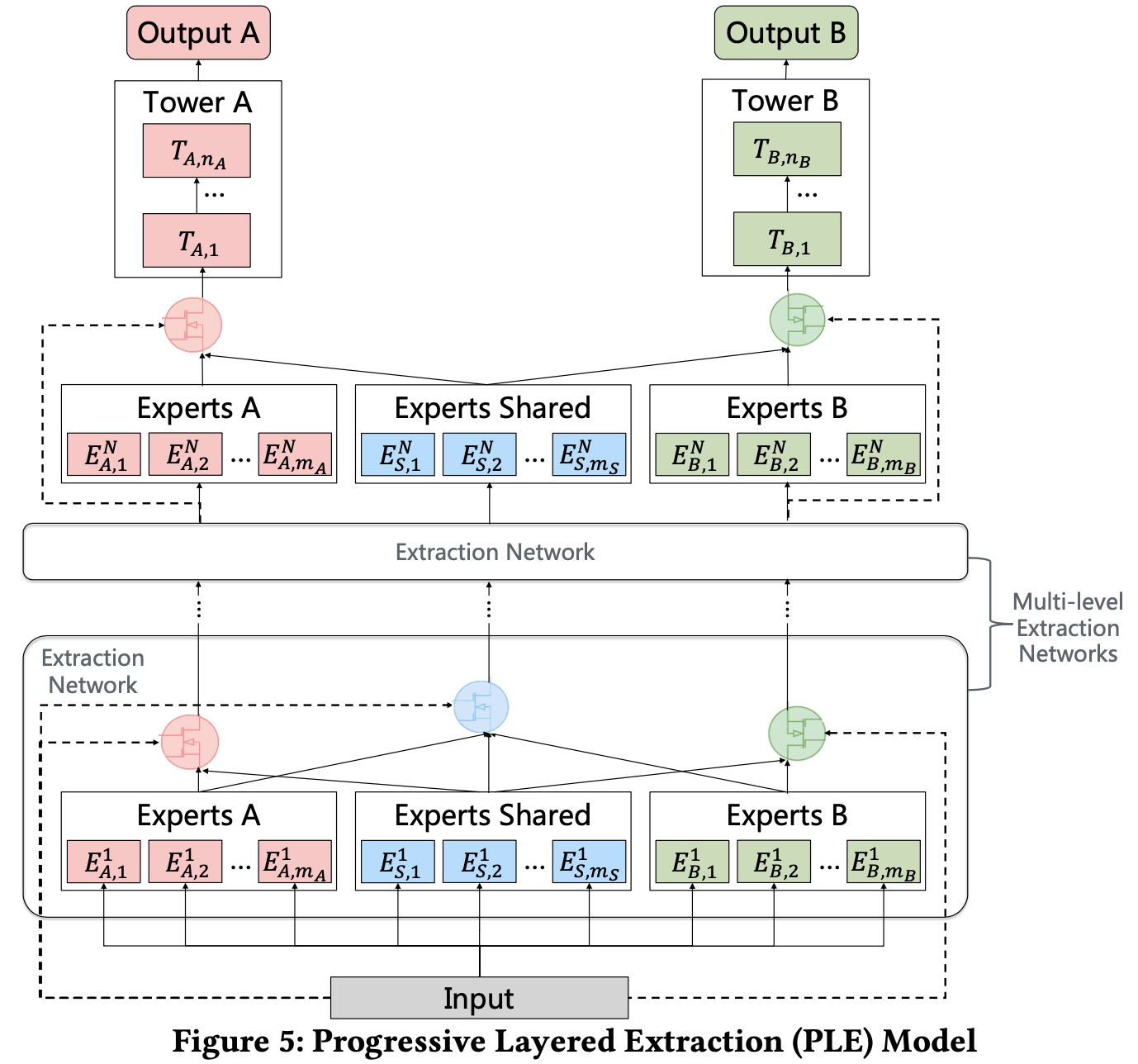
在多级提取网络中,**任务k的独享专家模块融合了上一层网络中任务k的独享专家模块和共享专家模块,而共享专家模块则融合了上一层所有的专家模块**。所以在多级提取网络中有两个门控,for独享专家模块和 for共享专家模块。所以在PLE中,不同任务的参数并不是像CGC中完全分离的,而是在顶层网络中分离的。在高层提取网络中的门控网络将低层提取网络中门控的融合结果作为选择器,而不是input。论文给出的理由是it may provide better information for selecting abstract knowledge extracted in higher-level experts。
PLE中权重函数、选择矩阵和门控网络的计算与CGC中的相同。 具体来说,PLE的第j个提取网络中任务k的门控网络的公式为:

**和MMOE相比,PLE增加了不同的Expert之间交互**。
3 loss设计
loss好像没有什么特别的地方。


