解决tf1.15中tf.scatter_update()函数没有定义梯度的问题
在本地使用了tf.compat.v1.scatter_update()更新tensor的值,测试OK放到服务器上跑一直失败,报错LookupError: No gradient defined for operation 'ScatterUpdate' (op type: ScatterUpdate),最后发现疑似tf1.15的tf.scatter_update()没有实现反向求导逻辑,挺奇怪的。
在本地使用了tf.compat.v1.scatter_update()更新tensor的值,测试OK放到服务器上跑一直失败,报错LookupError: No gradient defined for operation 'ScatterUpdate' (op type: ScatterUpdate),最后发现疑似tf1.15的tf.scatter_update()没有实现反向求导逻辑,挺奇怪的。
今天花了一个半小时对hexo博客进行格式美化,web端正常显示,但是在iPhone下,无论是Safari还是chrome,代码字体都特别大,疑似和ios下的渲染有关系,解决办法也很简单,设置webkit-text-size-ajust=none即可,但是注意该参数不要定义为全局的,因为设置为none的意思是禁止字体缩放。
昨天下午写tf代码的时候遇到一个报错tensorflow.python.framework.errors_impl.InvalidArgumentError: indices[0] = 24 is not in [0, 24),怀疑是矩阵变换哪里出了问题,但是check了很久的逻辑没有发现任何问题,甚至将相关逻辑抽取出来做了单元测试,依然没有任何发现。今天决定check下数据是否有问题,虽然之前已经check没有问题,但由于没有头绪,还是决定再次check下数据。打印了找了一个part的数据(tfrecord格式)重新打印成明文,根据batch数据的值找到对应的源数据,发现已经到达数据的末尾,突然意识到了什么…貌似是最后的数据量 < batch_size导致了报错,竟然没有想到。。。
tensorboard是Google提出的一个机器学习可视化的工具,它的界面上有一个smoothing的参数,通过调整smoothing可以控制指标曲线的平滑程度。那么它背后的原理是什么呢?
今天在开发spark项目中,发现用maven打包spark项目有一定的概率无法把json配置文件打包到jar中,有点疑惑。问了下同事,才知道配置相关文件要放到resources目录下,在打包过程中,maven会把resources下的资源放到jar包的根目录,在项目中就可以按照/xx.json的方式引入文件。
在做机器学习研究时,我们通常使用spark生成正负样本,如果是自己通过随机采样的方式生成负样本时,会有一个正负样本union的过程,这时候如果正负样本无法随机打散的话,可能会导致正负样本扎堆,在模型遇到正样本或者负样本之前就已经收敛了,这并不是我们所期望的,所以用spark将样本随机打散是一个非常必要的过程。
github仓库上传了一些图片但是在windows下用各种浏览器都无法查看,报错Failed to load resource: net::ERR_NAME_NOT_RESOLVED,上网查了下好像是github图片服务器被dns污染了,所以查不到,可以通过配置本机hosts文件的方式访问github图片服务器。
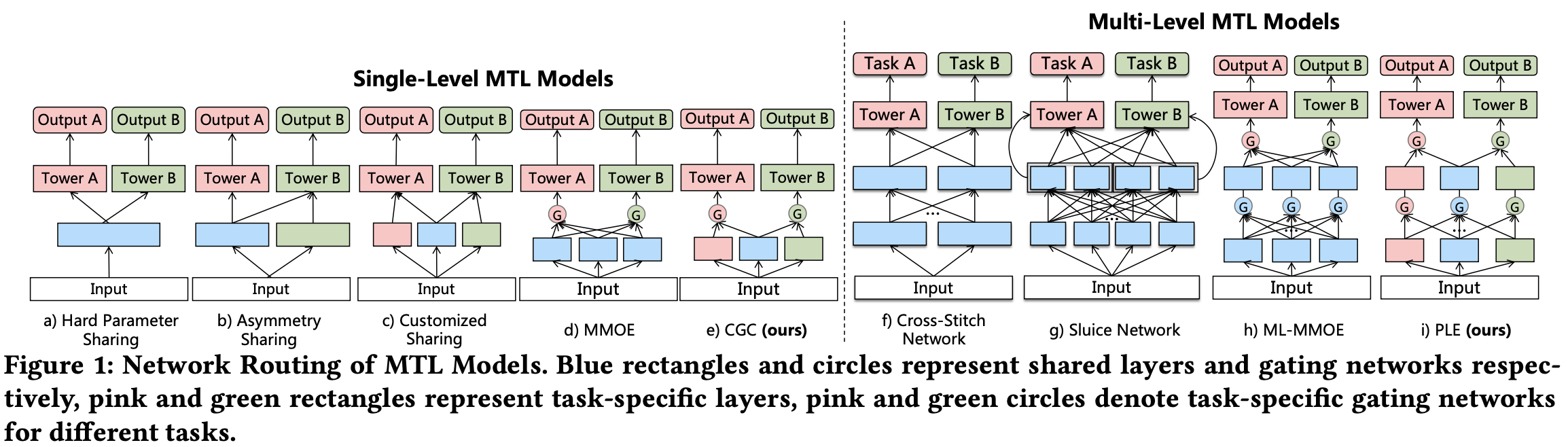
多任务学习的典型工作有多独立塔DNN,多头DNN,MOE,MMOE等工作,今天介绍的是腾讯的PLE(Progressive Layered Extraction)模型,PLE重点解决了多任务学习中存在的跷跷板现象(seesaw phenomenon)。多任务学习(MTL)并被证明可以通过任务之间的信息共享来提高学习效率。 然而,多个任务经常是松散相关甚至是相互冲突的,这可能导致性能恶化,这种情况称为负迁移 。 在论文中提到,通过在真实世界的大规模视频推荐系统和公共基准数据集上的大量实验,发现现有的 MTL 模型经常以牺牲其他任务的性能为代价来改进某些任务,当任务相关性很复杂并且有时依赖于样本时,即与相应的单任务模型相比,多个任务无法同时改进,论文中称之为跷跷板现象。