Hive基础教程
本来想对官方文档《Hive Tutorial》进行翻译整理的,但是发现网上已经有人做了这方面工作,就不重复造轮子了。将作者 strongyoung88 的博文转载了过来备查,建议查看原文《Hive 教程(官方Tutorial)》。
目录
- 概念
- 什么是 Hive
- Hive 的局限
- 快速入门
- 数据单元
- 类型系统
- 内置运算符和函数
- 语言能力
- 使用和示例
- 创建、展示、修改、删除 hive 表
- 加载数据
- 查询和插入数据
一 概念
1.1 Hive是什么
Hive是一个基于Apache Hadoop的数据仓库。对于数据存储与处理,Hadoop提供了主要的扩展和容错能力。
Hive设计的初衷是:对于大量的数据,使得数据汇总,查询和分析更加简单。它提供了SQL,允许用户更加简单地进行查询,汇总和数据分析。同时,Hive的SQL给予了用户多种方式来集成自己的功能,然后做定制化的查询,例如用户自定义函数(User Defined Functions,UDFs).
1.2 Hive不适合做什么
Hive不是为在线事务处理而设计。它最适合用于传统的数据仓库任务。
1.3 Getting Started
对于Hive, HiveServer2 和Beeline的设置详情,请参考 指南 。
对于学习Hive,这些 书单 可能对你有所用处。
以下部分提供了一个关于Hive系统功能的教程。先描述数据类型,表和分区的概念,然后使用例子来描述Hive的功能。
1.4 数据单元
根据颗粒度的顺序,Hive数据被组织成:
数据库:命名空间功能,为了避免表,视图,分区,列等等的命名冲突。数据库也可以用于加强用户或用户组的安全。
表:相同数据库的同类数据单元。例如表page_views,表的每行包含以下列:
- timestamp -这是一个INT类型,是当页面被访问时的UNIX时间戳。
- userid -这是一个BIGINT类型,用于惟一识别访问页面的用户。
- page_url -这是一个STRING类型,用于存储页面地址。
- referer_url -这是一个STRING类型,用于存储用户是从哪个页面跳转到本页面的地址。
- IP -这是一个STRING类型,用于存储页面请求的IP地址。
分区:每个表可以有一个或多个用于决定数据如何存储的分区键。分区(除存储单元之外)也允许用户有效地识别满足指定条件的行;例如,STRING类型的date_partition和STRING的country_partition。这些分区键的每个唯一的值定义了表的一个分区。例如,所有的“2009-12-23”日期的“US”数据是表page_views的一个分区。(注意区分,分区键与分区,如果分区键有两个,每个分区键有三个不同的值,则共有6个分区)。因此,如果你只在日期为“2009-12-23”的“US”数据上执行分析,你将只会在表的相关数据上执行查询,这将有效地加速分析。然而要注意,那仅仅是因为有个分区叫2009-12-23,并不意味着它包含了所有数据,或者说,这些数据仅仅是那个日期的数据。用户需要保证分区名字与数据内容之间的关系。分区列是虚拟列,它们不是数据本身的一部分,而是源于数据加载。
桶(Buckets or Clusters):每个分区的数据,基于表的一些列的哈希函数值,又被分割成桶。例如,表page_views可能通过userid分成桶,userid是表page_view的一个列,不同于分区列。这些桶可以被用于有效地抽样数据。
1.5 类型系统
Hive支持原始类型和复要类型,如下所述,查看 Hive Data Types。
1.5.1 原始类型
类型与表的列相关。支持以下原始类型:
Integers(整型)
- TINYINT -1位的整型
- SMALLINT -2位的整型
- INT -4位的整型
- BIGINT -8位的整型
布尔类型
- BOOLEAN -TRUE/FALSE
浮点数
- FLOAT -单精度
- DOUBLE -双精度
定点数
- DECIMAL -用户可以指定范围和小数点位数
字符串
- STRING -在特定的字符集中的一个字符串序列
- VARCHAR -在特定的字符集中的一个有最大长度限制的字符串序列
- CHAR -在特定的字符集中的一个指定长度的字符串序列
日期和时间
- TIMESTAMP -一个特定的时间点,精确到纳秒。
- DATE -一个日期
二进制
- BINARY -一个二进制位序列
1.5.2 复杂类型
复杂类型可以由原始类型和其他组合类型构建:
- 结构体类型(Stuct): 使用点(.)来访问类型内部的元素。例如,有一列c,它是一个结构体类型{a INT; b INT},字段a可以使用表达式c.a来访问。
- Map(key-value键值对):使用[‘元素名’]来访问元素。例如,有一个MapM,包含’group’->gid的映射,则gid的值可以使用M[‘group’]来访问。
- 数组:数组中的元素是相同的类型。可以使用[n]来访问数组元素,n是数组下标,以0开始。例如有一个数组A,有元素[‘a’,’b’,’c’],则A[1]返回’b’。
1.6 内置运算符和函数
Hive所有关键词的大小写都不敏感,包括Hive运算符和函数的名字。
1.6.1 内置运算符
关系运算

数学运算
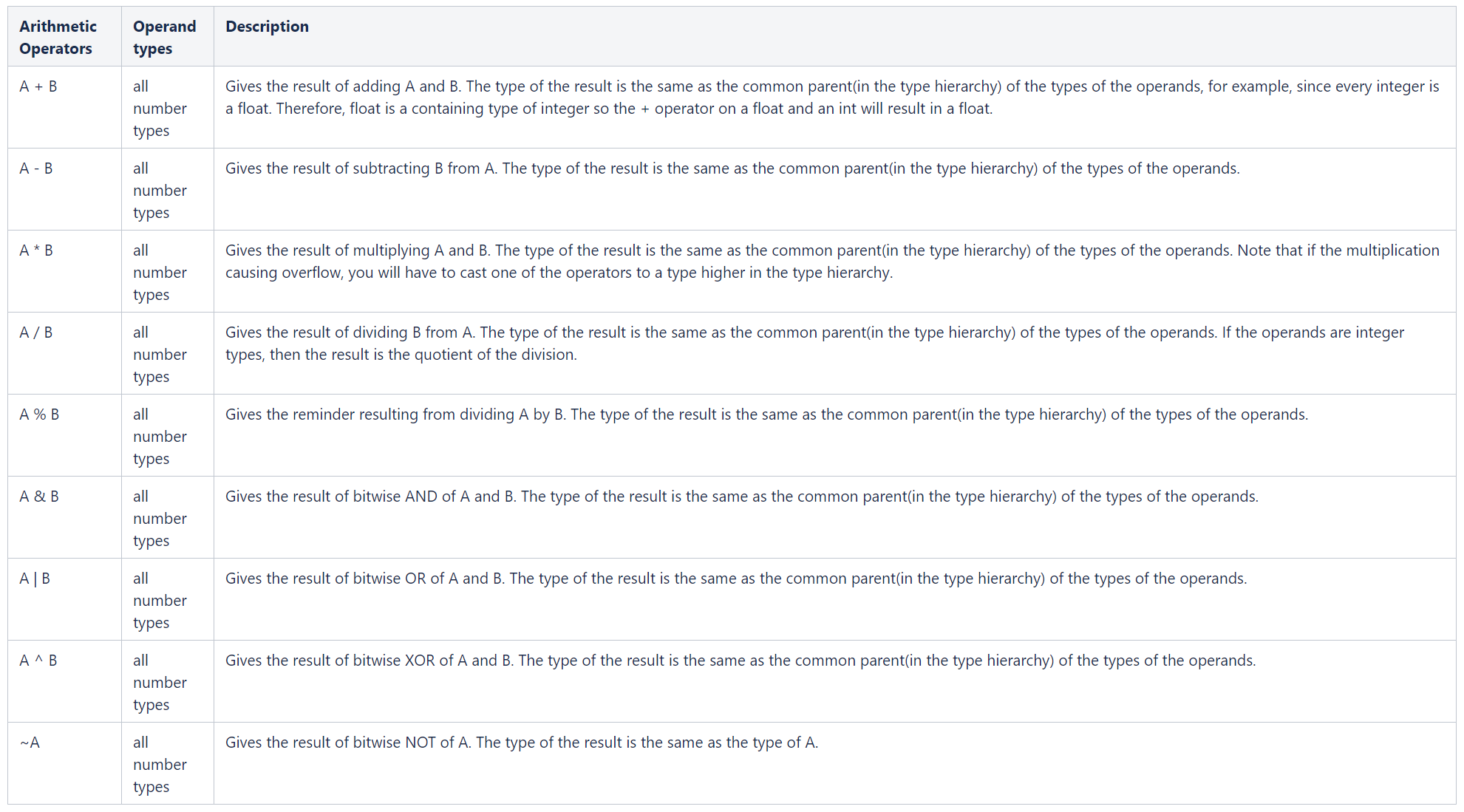
逻辑运算
复杂类型的运算

1.6.2 内置函数
Hive支持以下内置函数
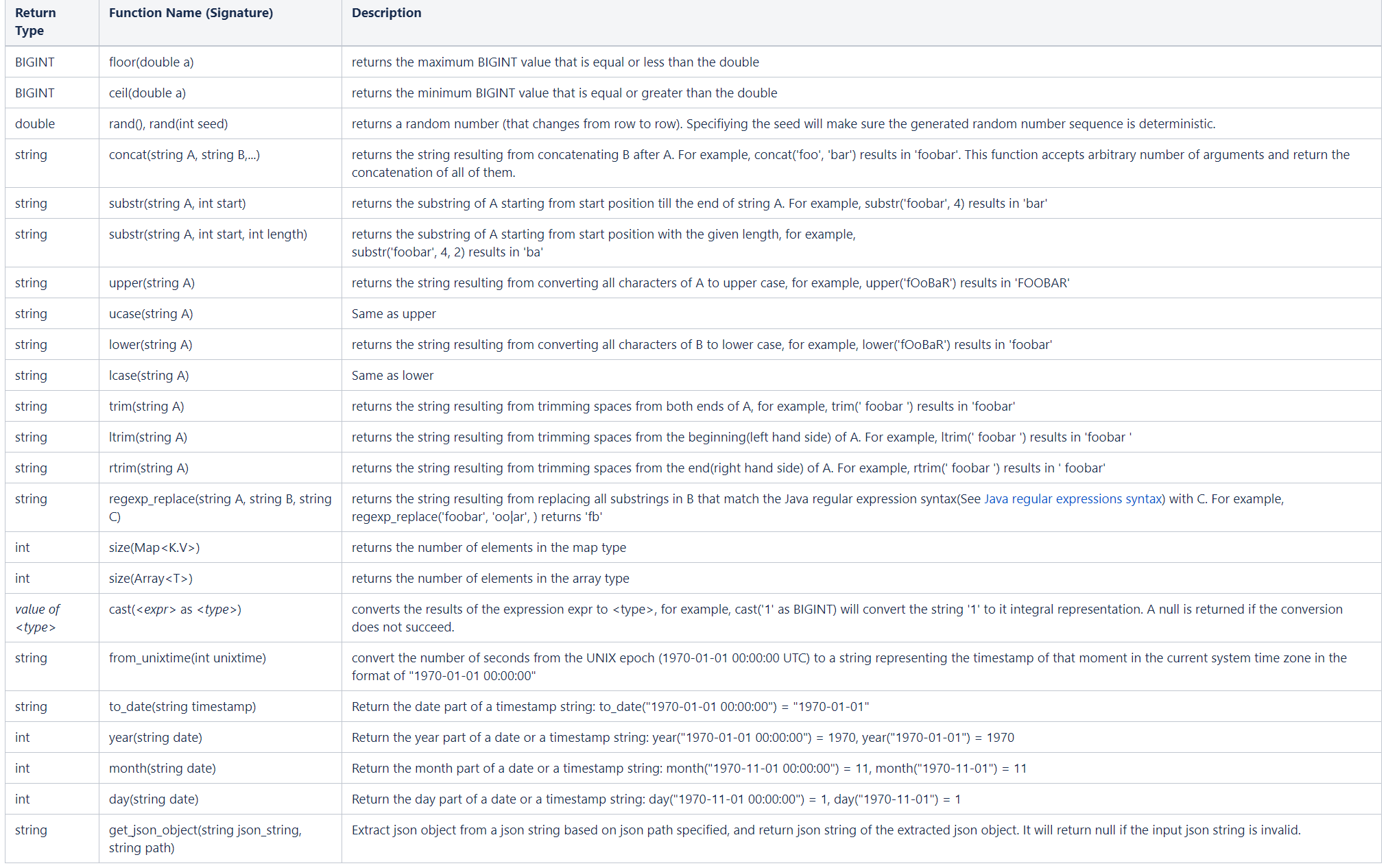
Hive支持以下内置聚合函数

1.7 语言能力
Hive’s SQL提供了基本的SQL操作。这些操作工作于表或分区上。这些操作是:
- 可以使用WHERE从表中筛选行
- 可以使用SELECT从表中查询指定的列
- 两个表之间可以join
- 可以在多个group by的列上使用聚合
- 可以存储查询结构到另一个表
- 可以下载表的内容到本地目录
- 可以存储查询结果到hadoop的分布式文件系统目录上
- 可以管理表和分区(创建,删除和修改)
- 可以使用自定义的脚本,来定制map/reduce作业
二 使用和实例
以下的例子有一些不是最新的,更多最新的信息,可以参考 LanguageManual。
以下的例子强调了Hive系统的显著特征。详细的查询测试用例和相应的查询结果可以在 Hive Query Test Cases 上找到。
- 创建,显示,修改,和删除表
- 加载数据
- 查询和插入数据
2.1 创建,显示,修改,和删除表
2.1.1 创建表
以下例子创建表page_view:
1 | CREATE TABLE page_view(viewTime INT, userid BIGINT, |
在这个例子中,表的列被指定相应的类型。备注(Comments)可以基于列级别,也可以是表级别。另外,使用PARTITIONED关键词定义的分区列与数据列是不同的,分区列实际上不存储数据。当使用这种方式创建表的时候,我们假设数据文件的内容,字段之间以ASCII 001(ctrl-A)分隔,行之间以换行分隔。
如果数据不是以上述格式组织的,我们也可以指定分隔符,如下:
1 | CREATE TABLE page_view(viewTime INT, userid BIGINT, |
目前,行分隔符不能改变,因为它不是由Hive决定,而是由Hadoop分隔符。
对表的指定列进行分桶,是一个好的方法,它可以有效地对数据集进行抽样查询。如果没有分桶,则会进行随机抽样,由于在查询的时候,需要扫描所有数据,因此,效率不高。以下例子描述了,在表page_view的userid列上进行分桶的例子:
1 | CREATE TABLE page_view(viewTime INT, userid BIGINT, |
以上例子,通过一个userid的哈希函数,表被分成32个桶。在每个桶中的数据,是以viewTime升序进行存储。这样组织数据允许用户有效地在这n个桶上进行抽样。合适的排序使得内部操作充分利用熟悉的数据结构来进行更加有效的查询。
1 | CREATE TABLE page_view(viewTime INT, userid BIGINT, |
在这个例子,CLUSTERED BY指定列进行分桶,以及创建多少个桶。行格式分隔符指定在hive表中,行如何存储。在这种分隔符情况下,指定了字段是如何结束,集合项(数组和map)如何结束,以及map的key是如何结束的。STORED AS SEQUENCEFILE表示这个数据是以二进制格式进行存储数据在hdfs上。对于以上例子的ROW FORMAT的值和STORED AS表示系统默认值。
表名和列名不区分大小写。
2.1.2 浏览表和分区
1 | SHOW TABLES; |
列出数据库里的所有的表,也可以这么浏览:
1 | SHOW TABLES 'page.*'; |
这样将会列出以page开头的表,模式遵循Java正则表达式语法。
1 | SHOW PARTITIONS page_view; |
列出表的分区。如果表没有分区,则抛出错误。
1 | DESCRIBE page_view; |
列出表的列和列的类型。
1 | DESCRIBE EXTENDED page_view; |
列出表的列和表的其他属性。这会打印很多信息,且输出的风格不是很友好,通常用于调试。
1 | DESCRIBE EXTENDED page_view PARTITION (ds='2016-08-08'); |
列出列和分区的所有属性。这也会打印出许多信息,通常也是用于调试。
2.1.3 修改表
对已有的表进行重命名。如果表的新名字存在,则报错:
1 | ALTER TABLE old_table_name RENAME TO new_table_name; |
对已有表的列名进行重命名。要确保使用相同的列类型,且要包含对每个已存在列的一个入口(也就是说,就算不修改其他列的列名,也要把此列另上,否则,此列会丢失)。
1 | ALTER TABLE old_table_name REPLACE COLUMNS (col1 TYPE, ...); |
对已有表增加列:
1 | ALTER TABLE tab1 ADD COLUMNS (c1 INT COMMENT 'a new int column', c2 STRING DEFAULT 'def val'); |
注意:
模式的改变(例如增加列),保留了表的老分区,以免它是一个分区表。所有对这些列或老分区的查询都会隐式地返回一个null值或这些列指定的默认值。
2.1.4 删除表和分区
删除表是相当,表的删除会删除已经建立在表上的任意索引。相关命令是:
1 | DROP TABLE pv_users; |
要删除分区。修改表删除分区:
1 | ALTER TABLE pv_users DROP PARTITION (ds='2016-08-08') |
注意:此表或分区的任意数据都将被删除,而且可能无法恢复。
2.2 加载数据
要加载数据到Hive表有许多种方式。用户可以创建一个“外部表”来指向一个特定的HDFS路径。用这种方法,用户可以使用HDFSput或copy命令,复制一个文件到指定的位置,并且附上相应的行格式信息创建一个表指定这个位置。一旦完成,用户就可以转换数据和插入他们到任意其他的Hive表中。例如,如果文件/tmp/pv_2016-06-08.txt包含逗号分隔的页面访问记录。这需要以合适的分区加载到表page_view,以下命令可以完成这个目标:
1 | CREATE EXTERNAL TABLE page_view_stg(viewTime INT, userid BIGINT, |
其中,‘44’是逗号的ASCII码,‘12’是换页符(NP from feed,new page)。null是作为目标表中的数组和map类型插入,如果指定了合适的行格式,这些值也可以来自外部表。
如果在HDFS上有一些历史数据,用户想增加一些元数据,以便于可以使用Hive来查询和操纵这些数据,这个方法是很有用的。
另外,系统也支持直接从本地文件系统上加载数据到Hive表。表的格式与输入文件的格式需要相同。如果文件/tmp/pv_2016-06-08包含了US数据,然后我们不需要像前面例子那样的任何筛选,这种情况的加载可以使用以下语法完成:
1 | LOAD DATA LOCAL INPATH /tmp/pv_2016-06-08_us.txt INTO TABLE page_view PARTITION(date='2016-06-08', country='US') |
路径参数可以是一个目录(这种情况下,目录下的所有文件将被加载),一个文件,或一个通配符(这种情况下,所有匹配的文件会上传)。如果参数是目录,它不能包含子目录。同样,通配符只匹配文件名。
在输入文件/tmp/pv_2016-06-08.txt非常大的情况下,用户可以采用并行加载数据的方式(使用Hive的外部工具)。只要文件在HDFS上-以下语法可以用于加载数据到Hive表:
1 | LOAD DATA INPATH '/user/data/pv_2016-06-08_us.txt' INTO TABLE page_view PARTITION(date='2016-06-08', country='US') |
对于这个例子,我们假设数组和map在文件中的值为null。
更多关于加载数据到表的信息,请参考 Hive Data Manipulation Language,创建外部表的另外一个例子请参考 External Tables。
2.3 查询和插入数据
- Simple Query
- Partition Based Query
- Joins
- Aggregations
- Multi Table/File Inserts
- Dynamic-Partition Insert
- Inserting into Local Files
- Sampling
- Union All
- Array Operations
- Map (Associative Arrays) Operations
- Custom Map/Reduce Scripts
- Co-Groups
Hive查询操作在文档Select,插入操作在文档insert data into Hive Tables from queries和writing data into the filesystem from queries。
2.3.1 简单的查询
对于所有的活跃用户,可以使用以下查询格式:
1 | INSERT OVERWRITE TABLE user_active |
注意:不像SQL,我们老是插入结果到表中。随后我们会描述,用户如何检查这些结果,甚至把结果导出到一个本地文件。你也可以在Beeline或HiveCLI执行以下查询:
1 | SELECT user.* |
这在内部将会重写到一些临时文件,并在Hive客户端显示。
2.3.2 基于查询的分区
在一个查询中,要使用什么分区,是由系统根据where在分区列上条件自动的决定。例如,为了获取所有2008年3月份,从域名xyz.com过来的page_views,可以这么写查询:
1 | INSERT OVERWRITE TABLE xyz_com_page_views |
注意:在这里使用的page_views.date是用PARTITIONED BY(date DATATIME, country STRING)定义的.如果你的分区命名不一样,那么不要指望.date能够做你想做的事情,即无法获得分区的优势。
2.3.3 连接
表的连接可以使用以下命令:
1 | INSERT OVERWRITE TABLE pv_users |
想实现外连接,用户可以使用LEFT OUTER,RIGHT OUTER或FULL OUTER关键词来指示不同的外连接(左保留,右保留或两端都保留)。例如,想对上面的查询做一个FULL OUTER,相应的语法可以像下面这样:
1 | INSERT OVERWRITE TABLE pv_users |
为了检查key在另外一个表中是否存在,用户可以使用LEFT SEMI JOIN,正如以下例子一样:
1 | INSERT OVERWRITE TABLE pv_users |
为了连接多个表,可以使用以下语法:
1 | INSERT OVERWRITE TABLE pv_friends |
注意:Hive只支持equi-joins。所以,把最大的表放在join的最右边,可以得到最好的性能。
2.3.4 聚合
统计用户每个性别的人数,可以使用以下查询:
1 | INSERT OVERWRITE TABLE pv_gender_sum |
可以同时做多个聚合,然而,两个聚合函数不能同时用DISTINCT作用于不同的列,以下情况是可以的(DISTINCT作用于相同列):
1 | INSERT OVERWRITE TABLE pv_gender_agg |
然而,以下情况(DISTINCT作用于不同的列)是不允许的:
1 | INSERT OVERWRITE TABLE pv_gender_agg |
2.3.5 多表/文件插入
聚合或简单查询的输出可以插入到多个表中,或者甚至是HDFS文件(能够使用HDFS工具进行操纵)。例如,如果沿用前面的“性别分类”,例子如下:
1 | FROM pv_users |
第一个插入语句将结果插入到Hive表中,而第二个插入语句是将结果写到HDFS文件。
2.3.6 动态分区插入
在前面的例子中,我们知道,在插入语句中,只能有一个分区。如果我们想加载到多个分区,我们必须像以下描述来使用多条插入语句:
1 | FROM page_view_stg pvs |
为了加载数据到全部的country分区到指定的日期。我们必须在输入数据中为每个country增加一条插入语句。这是非常不方便的,因为我们需要提前创建且知道已存在哪些country分区列表。如果哪天这些country列表变了,我们必须修改我们的插入语句,也应该创建相应的分区。这也是非常低效的,因为每个插入语句可能都是转换成一个MapReduce作业。
动态分区插入(Dynamic-partition insert)(或multi-partition插入)就是为了解决以上问题而设计的,它通过动态地决定在扫描数据的时候,哪些分区应该创建和填充。这个新的特征是在版本0.6.0加入的。在动态分区插入中,输入列被评估,这行应该插入到哪个分区。如果分区没有创建,它将自动创建这个分区。使用这个特征,我们仅仅需要插入语桀犬吠尧来创建和填充所有需要的分区。另外,因为只有一个插入语句,相应的也只有一个MapReduce作业。相比多个插入语句的情况,这将显著地提高性能且降低Hadoop集群负载。
以下是使用一个插入语句,加载数据到所有country分区的例子:
1 | FROM page_view_stg pvs |
与多条插入语句相比,动态分区插入有一些语法上的不同:
- country出现在PARTITION后面,但是没有具体的值。这种情况,country就是一个动态分区列。另一方面,dt有一个值,这意味着它是一个静态的分区列。如果一个列是动态分区列,它的值将会使用输入列的值。目前,我们仅仅允许在分区条件的最后一列放置动态分区列,因为分区列的顺序,指示了它的层级次序(意味着dt是根分区,country是子分区)。我们不能这样指定分区(dt,country=’US’),因为这表示,我们需要更新所有的日期的分区且它的country子分区是‘US’。
- 一个额外的pvs.country列被加入在查询语句中。这对动态分区列来说,相当于输入列。注意:对于静态分区列,我们不需要添加一个输入列,因为在PARTITION语句中,它的值已经知道。注意:动态分区列的值(不是名字)查出来是有序的,且是放在select语句的最后。
动态分区插入的语义:
- 对于动态分区列,当已经此分区时,(例如,country=’CA’已存在dt根分区下面)如果动态分区插入与输入数据中相同的值(’CA’),它将会被重写(overwritten)。
2.3.7 插入到本地文件
在某些场合,我们需要把输出写到一个本地文件,以便于能用excel表格打开。这可以使用以下命令:
1 | INSERT OVERWRITE LOCAL DIRECTORY '/tmp/pv_gender_sum' |
2.3.8 抽样
抽样语句允许用户对数据抽样查询,而不是全表查询。当前,抽样是对那些在CREATE TABLE语句的CLUSTERED BY修饰的列上。以下例子,我们从表pv_gender_sum表中的32个桶中,选择第3个桶。
1 | INSERT OVERWRITE TABLE pv_gender_sum_sample |
通常,TABLESAMPLE的语法像这样:
1 | TABLESAMPLE(BUCKET x OUT OF y) |
这个y必须是桶的数量的因子或倍数,桶的数量是在创建表的时候指定的。抽样所选的桶由桶大小,y和x共同决定。如果y和桶大小相等,则抽样所选的桶是x对y的求模结果。
1 | TABLESAMPLE(BUCKET 3 OUT OF 16) |
这将抽样第3个和第19个桶。桶的编号从0开始。
tablesample语句的另一方面:
1 | TABLESAMPLE(BUCKET 3 OUT OF 64 ON userid) |
这将抽取第3个桶的一半。
2.3.9 union all
这个语言也支持union all,如果假设我们有两个不同的表,分别用来记录用户发布的视频和用户发布的评论,以下例子是一个union all 的结果与用户表再连接的查询:
1 | INSERT OVERWRITE TABLE actions_users |
2.3.10 数组操作
表的数组列可以这样:
1 | CREATE TABLE array_table (int_array_column ARRAY<INT>); |
假设pv.friends 是类型ARRAY
1 | SELECT pv.friends[2] |
这个查询得到的是pv.friends里的第三个元素。
用户也可以使用函数size来获取数组的长度,如下:
1 | SELECT pv.userid, size(pv.friends) |
2.3.11 Map(关联数组)操作
Map提供了类似于关联数组的集合。这样的结构不仅可以由程序创建。我们也将很快可以继承这个。假设pv.properties是类型map<String,String>,如下:
1 | INSERT OVERWRITE page_views_map |
这将查询表page_views的‘page_type‘属性。
与数组相似,也可以使用函数size来获取map的大小:
1 | SELECT size(pv.properties) |
2.3.12 定制Map/Reduce脚本
通过使用Hive语言原生支持的特征,用户可以插入他们自己定制的mapper和reducer在数据流中。例如,要运行一个定制的mapper脚本script-map_script和reducer脚本script-reduce_script),用户可以执行以下命令,使用TRANSFORM来嵌入mapper和reducer脚本。
注意:在执行用户脚本之前,表的列会转换成字符串,且由TAB分隔,用户脚本的标准输出将会被作为以TAB分隔的字符串列。用户脚本可以输出调试信息到标准错误输出,这个信息也将显示hadoop的详细任务页面上。
1 | FROM ( |
map脚本样本(weekday_mapper.py)
1 | import sys |
当然,对于那些常见的select转换,MAP和REDUCE都是“语法糖”。内部查询也可以写成这样:
1 | SELECT TRANSFORM(pv_users.userid, pv_users.date) USING 'map_script' AS dt, uid CLUSTER BY dt FROM pv_users; |
2.3.13 Co-Groups
在使用map/reduce的群体中,cogroup是相当常见的操作,它是将来自多个表的数据发送到一个定制的reducer,使得行由表的指定列的值进行分组。在Hive的查询语言中,可以使用以下方式,通过使用union all和cluster by来实现此功能。假设我们想对来自表actions_video和action_comment的行对uid列进行分组,且需要发送他们到reducer_script定制的reducer,可以使用以下语法:
1 | FROM ( |

