transformer是什么
transformer是近些年在NLP领域火起来的一个语言模型,google bert的出现更是将其推到了顶峰。所谓语言模型就是预测每个句子在语言中出现的概率。简单地说,transformer是基于attention和encode-decode的产物。transformer出自2017年的一篇论文《Attention Is All You Need》,最初是用来提高机器翻译的效率,后来逐渐演化为各类预训练模型(bert)的基础。基于transformser可以构建各种各样的NLP任务,只需要修改下训练样本,并进行微调就可以了。
transformer的细节可以参考李理的博客《Transformer图解》,讲的非常细致。transformer的模型结构如下:
如上图所示,其实transformer也是在encode-decode框架下做的,与此前不同的是,transformer提出了一种self-attention机制(自注意力机制),怎么理解呢?就是说之前的attention大多使用在seq2seq任务中,例如在机器翻译中,attention作用在源句子token(token就指的是单词或词语)和目标句子token之间,但是transformer的self-attention作用在源句子的token之间。
attention第一次提出在2014年的一篇论文《Neural Machine Translation by Jointly Learning to Align and Translate》,个人感觉这篇工作做的特别棒。这篇论文的核心如下:

意思就是基础的encode-decode框架使用一个固定长度的向量表达源句子的所有语义信息,这种做法造成了encode-decode框架的性能瓶颈,因为源句子中前面的词容易被后面词的信息覆盖,另外单一个固定长度的向量也无法充分表达一个句子的语义。论文提出了一种attention机制,自动找到在源句子中和预测目标词相关的词,基于这些词对目标词进行预测。论文很简单,不过如果看英文吃力的话也有中文版的:Microstrong的博客《深度学习中的注意力机制》。attention的逻辑如下所示(博客中的图4就是下图2):

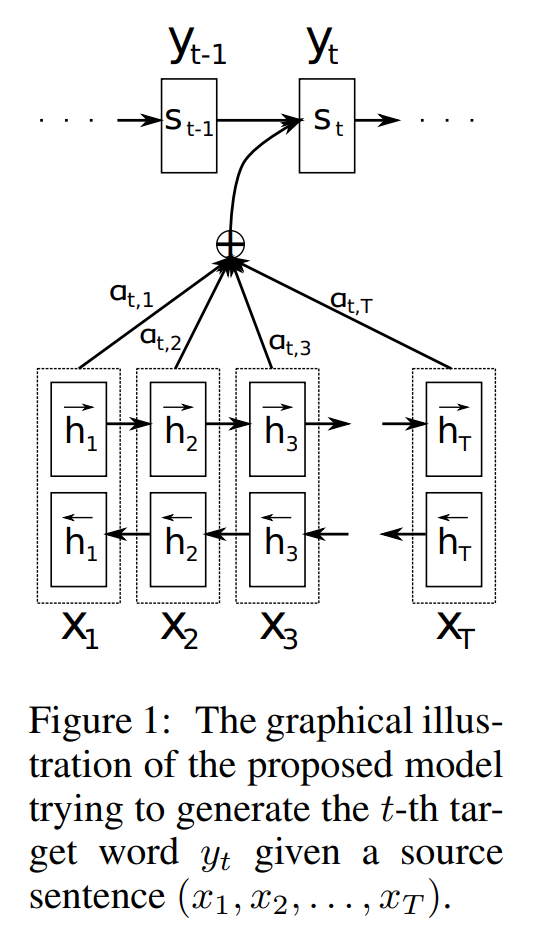
那么transformer做了哪些核心工作呢?个人总结有如下几点:
- 提出了self-attention机制,使得效果提升易于并行。在transformer中有两个注意力,一个是self-attention,在encoder和decoder中都有使用;一个是普通的attention,只在decoder中被使用,用来在每个decoder中self-attention的输出和encoder最后一层输出建立联系。
- 引入了位置编码;
- encode和decode具有不同的结构,decode多了一个普通的attention,使得encode的最后一层输出可以作用于decode的各个层,同1;
- 提出了层归一化的概念,本质上也是为了加速梯度求解吧,我觉得层归一化没有什么物理含义。
需要注意的是:
- 使用mask。因为使用transformer进行预测的时候,decoder是串行地一个时间步一个时间步进行预测的,不能使用未来信息,所以在训练decoder的时候也要避免使用未来信息,这时候就需要使用mask。【参考 变压器解码器掩模篇】不过在transformer有两种mask,一种是为了解决上述问题的,叫做Sequence mask;另一种是为了解决句子长短不一的问题的,叫做padding mask。具体可以参考《Transformer各层网络结构详解!面试必备!(附代码实现)》
- decoder的第一个时间步的输入是一个特殊的token,这个token主要目的是占位。目标序列开始的token(如
),也可能是源序列结尾的token(如 。),也可能是其它视任务而定的输入。等等,不同源码中可能有微小的差异,其目标则是预测下一个位置的单词(token)是什么,对应到time step为1时,则是预测目标序列的第一个单词(token)是什么,以此类推 - 在decoder中有一个普通的attention,即上图中的Multi-Head Attention,这个attention是将encoder的最后一层输出和当前decoder的第一个子模块(即上图中的Masked Multi-Head Attention)进行关联,Q就是encoder的最后一层输出,K,V就是Masked Multi-Head Attention的输出,使得当前的decoder对源序列的不同部分给予不同权重的注意力。

