《Inductive Matrix Conpletion Based On Graph Neural Network》论文阅读
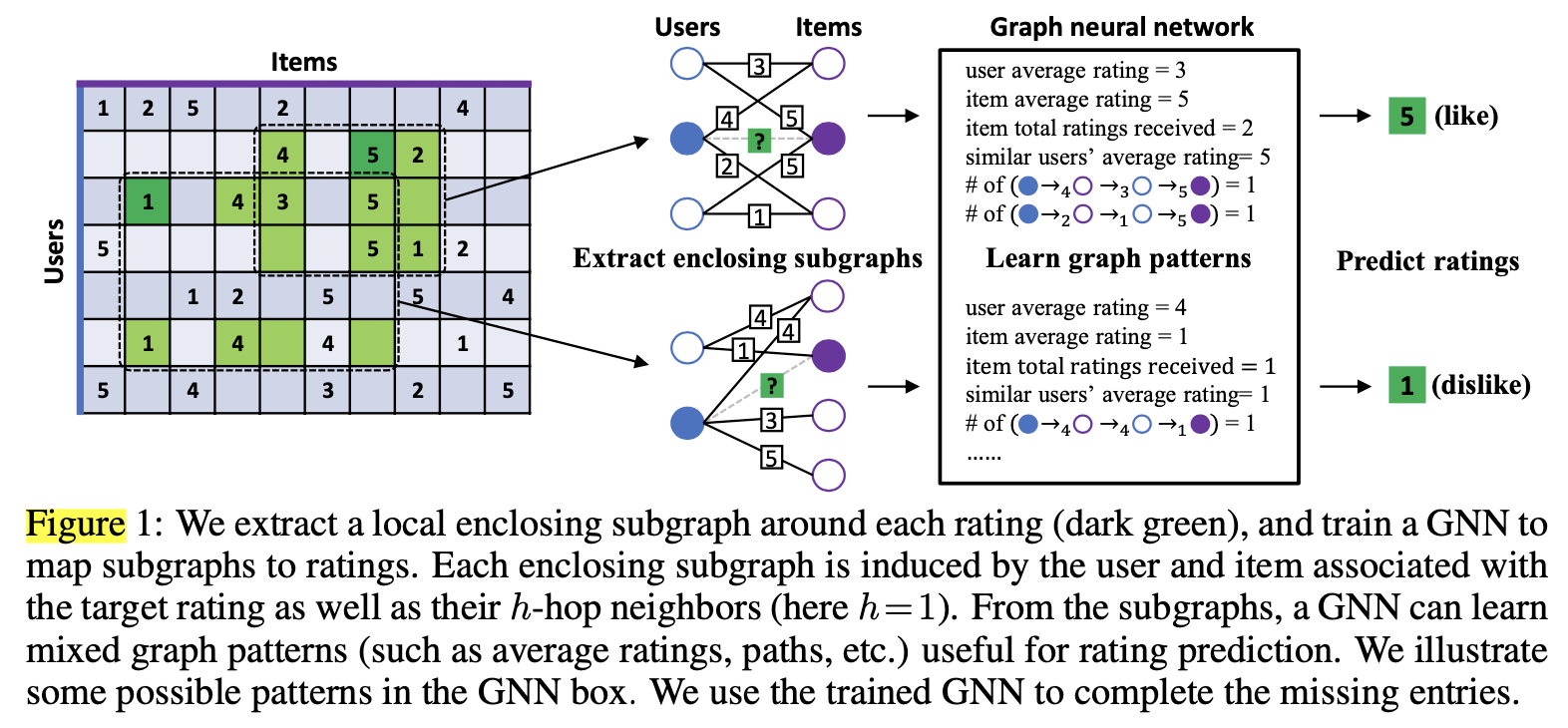
论文提出了一种不使用辅助信息的归纳(inductive)矩阵补全模型。通过将评分矩阵分解为行(用户)和列(物品)的低维隐向量的乘积,现有的大多数矩阵补全方法都是可转导(transductive)的,因为学习的向量无法泛化为看不见的行/列或新矩阵。为了使矩阵补全具有归纳性,之前大多数的工作都使用内容(辅助信息)进行预测,例如用户的年龄或电影类型。但是,内容并不总是高质量的,并且可能难以提取。在极端的情况下,除了要补全的矩阵之外没有其他辅助信息可用,这时我们就无法学习归纳矩阵补全模型。本文提出了一种基于归纳图的矩阵补全(IGMC)模型来解决此问题。 IGMC基于一跳子图训练图神经网络(GNN),并将这些子图映射到其对应的评分,一跳子图基于评分矩阵生成的用户-物品pair对生成。IGMC相比于最新的transductive基线实现了更好的性能。此外,IGMC是归纳性的,它可以推广到训练时未看到的用户/物品(假设二者存在相互作用),甚至可以推广到新任务上。我们的迁移学习实验表明,从MovieLens数据集中训练出的模型可以直接用于预测豆瓣电影收视率,并且性能出奇地好。我们的工作表明:1)可以在不使用辅助信息的情况下训练归纳矩阵补全模型,同时获得与最新的transductive方法相似或更好的性能; 2)用户-物品pair对周围的局部图模式是该用户对该物品评分的有效预测指标;和3)建模推荐系统时可能不需要长期依赖。
先说下inductive学习和transductive学习的区别 :
inductive学习,指的是训练数据和测试数据互斥的学习。模型从训练数据学习规律,然后在测试数据预测,训练数据和测试数据互斥。这样训练得到的模型泛化能力更强。
transductive学习,指的是训练数据和测试数据有重叠的学习。模型训练时会基于训练数据和测试数据的部分信息(不包括label信息)进行联合建模,然后在测试数据上预测label,例如在聚类学习中,分析X的分布然后预测Y,这点可以参考知乎用户望尼玛的回答《如何理解 inductive learning 与 transductive learning?》。
1 构造二部图
定义图G为无向二部图,其来源于评分矩阵R。在图G中,节点代表用户(u表示,代表评分矩阵中的一行)或者物品(v表示,代表评分矩阵中的一列),用户和物品之间存在边,但是用户之间和物品之间不能存在边。每条边的值r=$R_{u,v}$代表该用户对该物品的评分,定义$R$代表评分值的集合,例如在MovieLenszhong ,R={1,2,3,4,5}。定义$N_{r(u)}$为节点u的以r类型的边连接的邻居。
2 提取子图
IGMC的第一部分是提取封闭子图。对于每个观测到的评分值$R_{u,v}$,从G中提取一个从u到v的h跳封闭子图,算法1描述了提取h跳封闭子图的BFS算法。然后把这些子图喂到GNN中,然后回归其评分。对于测试集中的每个(u-v) pair对,同样从G中提取h跳封闭子图,然后使用训练得到的GNN模型预测其评分。需要注意的是,在提取了(u,v)的训练封闭子图之后,需要将(u,v)的边移除,因为目标是预测。

3 节点学习
IGMC第二部分是节点标记。因为封闭子图提取出来之后要喂给GNN,GNN无法区分不同的节点,所以需要对节点进行标记,1是要区分目标节点和上下文节点(目标节点指的是我们将要预测的用户对物品的评分);2是要区分用户节点和物品节点。为此论文提出了一种节点标记方法:首先定义目标用户和目标物品的标签为0和1,对i跳的上下文用户标记为2i,对i跳的上下文物品标记为2i+1。然后将这些标记转化为one-hot向量,将其节点的初始特征输入GNN。这里同时也区分了不同阶的节点,因为不同阶的节点对目标节点的贡献程度不同。
需要注意的是,虽然我们已经证明了上述方法具有很好的性能,但它并不是唯一的节点标记方法。这些节点标签的one-hot编码将被用于子图节点特征的初始化,然后喂给GNN。节点标签完全依赖于封闭子图,和全局二部图无关。给定一个封闭子图,即使它的节点来自于不同的二部图,我们也可以预测其评分,因为IGMC完全依赖于局部封闭子图的图模式,而没有利用任何二部图的全局信息。节点标签也不同于在GC-MC中使用全局节点ID,Using one-hot encoding of global IDs is essentially transforming the first message passing layer’s parameters into latent node embedding associated with each particular ID (equivalent to an embedding lookup table). Such a model cannot generalize to nodes whose IDs are out of range, thus is transductive.
4 图神经网络架构
IGMC的第三部分是训练图神经网络模型预测封闭子图的评分。在以前基于节点的方法中,例如GC-MC,一个节点级的GNN应用于整个二部图以提取节点向量。然后,节点u和v的向量被输入到内积或者双线性算子中(bilinear operator),以重建(u,v)评分。而IGMC是将图级别的GNN应用于(u, v)的封闭子图,并将子图映射到评分。因此,IGMC的GNN有两个组件:(1)消息传递层,为子图中的每个节点提取一个特征向量;(2)一个池化层,抽象这些节点特征的子图表达。
为了从不同的边类型中学习丰富的图模式,这里采用了R-GCN(relational graph convolutional operator)算子作为GNN的消息传递层,形式如下:
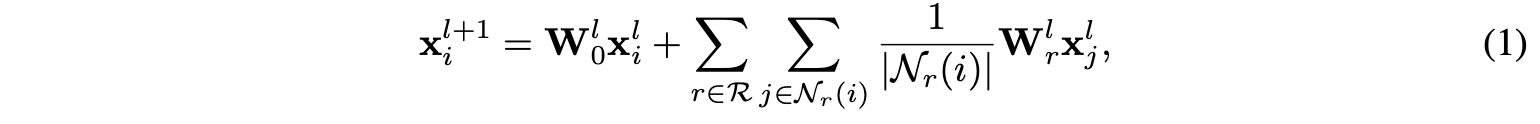
其中$X^l_i$表示节点i在$l$层的特征向量,$W_0^l$和 $W_r^l|r \in R$是可学习的参数矩阵。由于连接邻居j到节点i的边r是由不同的参数矩阵$W^l_r$,我们可以从边类型中学习丰富的图模式,例如目标用户对物品的平均评分,目标物品得到的平均分,两个目标节点通过哪条路径连接,等等。
这里我们简要介绍下RGCN。RGCN的目的是解决GCN忽略不同边关系对节点的影响的问题,其主要形式如下:
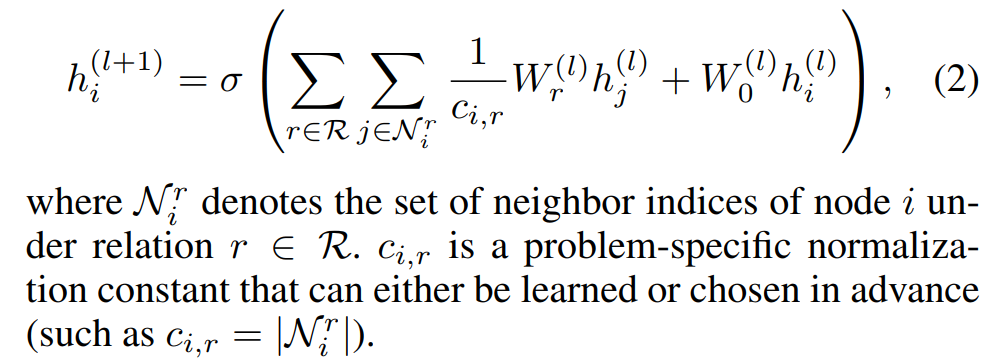
$N_i^r$表示节点i的关系为r的邻居节点集合,$c_{i,r}$是一个正则化常量, 其中$c_{i,r}$的取值是$|N_i^r|$。$W_r^{(l)}$是线性转化函数,将同类型边的邻居节点,使用用一个参数矩阵$W_r^{(l)}$进行转化。此公式和GCN不同的是,不同边类型所连接的邻居节点,进行一个线性转化,$W_r^{(l)}$的个数也就是边类型的个数,论文中称为relation-specific。这里还可以设置更加灵活的函数,例如多层神经网络[1]。
我们在两个层之间堆叠具有tanh激活的L个消息传递层。(follow Zhang等人,2018; Xu等人,2018的工作),来自不同层的节点i的特征向量被拼接起来作为其最终表达形式$h_i$:
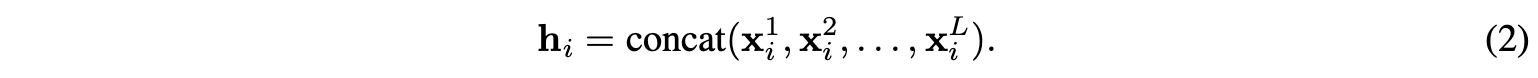
接下来,我们对节点表达进行池化得到一个图级别的特征向量。池化方式有多种,例如求和,均值,SortPooling(Zhang et al., 2018),DiffPooling (Ying et al., 2018b)。在论文中使用了一个和上述不同的池化层,其拼接目标用户和物品的最终表达作为图表达。
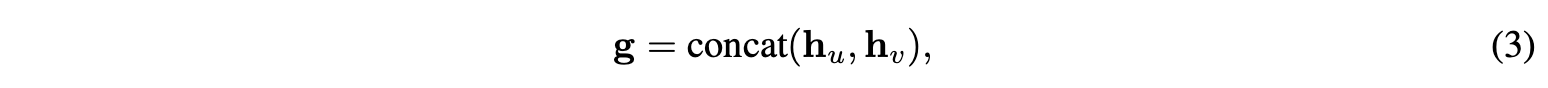
$h_u$表示目标用户的最终表达,$h_v$是目标物品的最终表达。之所以要这么做(拼接目标用户和物品的最终表达作为图表达),是因为与其它上下文相比,这两个节点更重要,尽管这样做很简单,但是我们验证了在矩阵补全任务中,这种方式的性能明显优于其它池化层。
在得到最终的图表达之后,使用MLP输出预测评分:
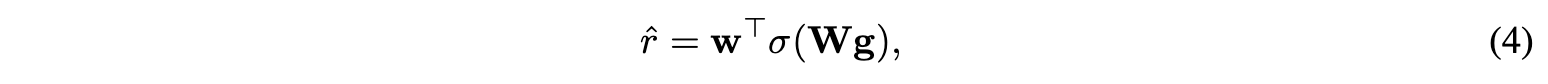
W和w是MLP的参数,$\hat{r}$是标量评分,$\sigma$是激活函数,论文中使用了ReLU。
5 模型训练
损失函数,最小化预测得分和真实得分的均方误差(MSE):
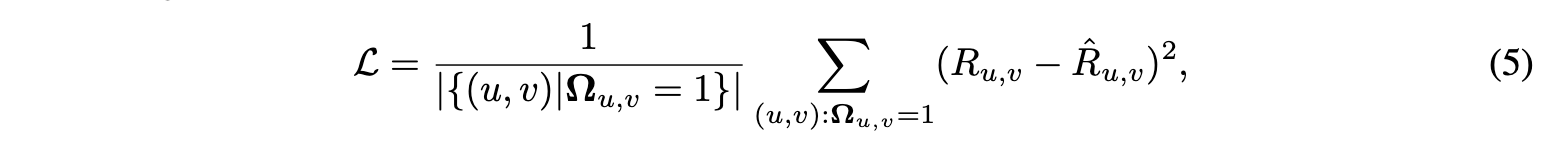
$R_{u,v}$表示真实得分,$\hat{R}_{u,v}$是预测得分。$\Omega$是0/1掩码矩阵,表示评分矩阵R中的可观测条目。
相邻评分正则化,GNN中使用的R-GCN层,(1)对于不同的评级类型具有不同的参数$W_r$。 一个缺点是它没有考虑到评分值的大小。 例如,MovieLens中的4级和5级都表示用户喜欢该电影,而1级则表明用户不喜欢该电影。 理想情况下,我们希望我们的模型意识到这样一个事实,即4评分比1更接近5。 但是,在R-GCN中,评分值1,4和5仅被视为三种独立的边缘类型,评分值的大小和顺序信息完全丢失。 为了解决这个问题,论文提出了一种相邻的评分正则化(ARR)技术,该技术使得相近的评分具有相似的参数矩阵。 假设R中的评分具有$r_1$,$r_2$,…$r|R|$的顺序, 这表明用户对商品的偏好越来越高。 然后,ARR正则化器为:
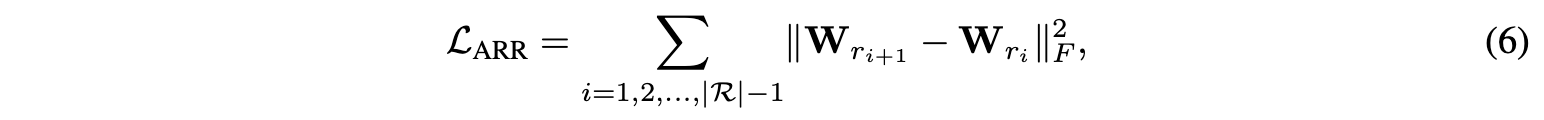
其中${\lVert \cdot \lVert}_F$表示矩阵的Frobenius范数。 上述正则化器可抑制相近评分参数矩阵之间的差异过大,这不仅考虑了评分顺序,而且还通过迁移相近评分的知识来帮助优化那些不经常使用的评分。 最终损失函数由下式给出:
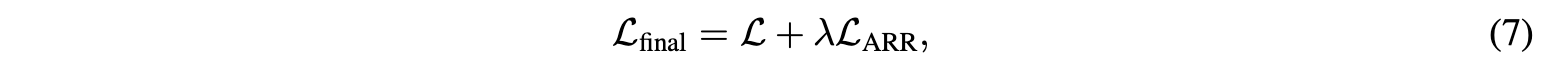
$\lambda$权衡了MSE损失和ARR调整器的重要性。 还有很多方法可以对评分值的大小和顺序进行建模,这些方法留待以后的工作。

